Kunde
Ein Unternehmen, das eine Gesundheitsplattform entwickelt, beauftragte Elinext mit der Entwicklung eines Diagnosetools für Lungenentzündung.
Herausforderung
Das Unternehmen hat eine umfassende Gesundheitsplattform entwickelt. Die Behandlung von Lungenentzündung war aufgrund von COVID einer seiner Schwerpunktbereiche, und es wollte ein Instrument zur Diagnose von Lungenentzündung für die Plattform entwickeln.
Das Tool sollte Lungenröntgenbilder analysieren und mithilfe von maschinellem Lernen (ML), einer Technik der künstlichen Intelligenz (KI), Anzeichen einer Lungenentzündung erkennen. Das Unternehmen hatte keine relevanten internen Experten, also suchte es nach Hilfe und fand sie bei Elinext.
Lösung
Wir fangen mit der Suche nach einem neuronalen Netzwerk an, das Lungenbilder am besten analysiert und fanden vier Kandidaten: ResNet (50, 101, 152), VGG (16, 19), MobileNet und Inception (V2, V3). Nachdem wir uns eingehender mit jedem von ihnen befasst hatten, haben wir uns für InceptionV3 entschieden, das von Google Research Lab entwickelt wurde.
Nachdem wir uns für unser neuronales Netz entschieden hatten, gingen wir zum Entwerfen der Softwarearchitektur und zum Trainieren des Algorithmus über.
Architektur
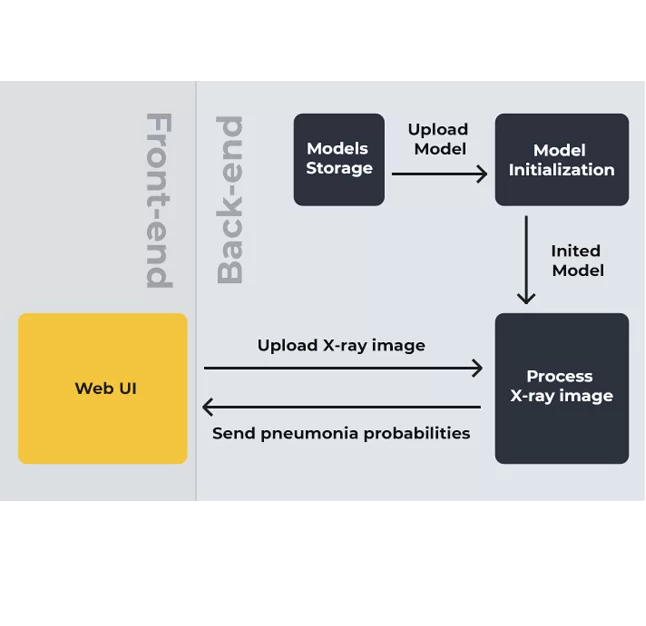
Die Software basiert auf Web-Technologie und kann in andere Systeme wie Desktop-Anwendungen und mobile Apps integriert werden.
Wir haben öffentlich verfügbare Frameworks, Bibliotheken und Technologien verwendet, um die Software zu entwickeln. Um eine statische HTML5-Webseite zu erstellen, haben wir einen Webserver in einem Docker-Container bereitgestellt. Auf dieser Seite kann ein Benutzer ein Lungenbild hochladen und Feedback erhalten. Das Bild wird zur Verarbeitung über das HTTP-Protokoll gesendet.
Training
Training ist der schwierigste Teil beim Erstellen von ML-Algorithmen. Ihre Fähigkeit, genügend Daten zu beschaffen, Fehler zu vermeiden und während des gesamten Prozesses konsistent zu sein, kann den Algorithmus entscheiden oder zerstören.
Manuelles Training ist oft inkonsistent. Sie können vergessen, welche Schritte Sie in welcher Reihenfolge unternommen haben, oder gelegentlich Protokolle löschen. Infolgedessen können Sie eine Trainingseinheit nicht genau wiederholen. Deshalb haben wir den Prozess von A bis Z automatisiert.
Wir mussten komplexe Modelle mit riesigen Datensätzen schnell trainieren. Dazu haben wir eine Amazon Web Services (AWS) g3s.xlarge-Instance gemietet und Deep Learning Base AMI (Ubuntu 18.10) verwendet. Letzteres ist eine leistungsstarke Maschine mit 16 GB RAM, einer 4-Kern-CPU und einer Nvidia Tesla M60-GPU. Es war perfekt für die Aufgabe geeignet.
Nachdem wir uns für die Technologie entschieden haben, konnte das Training beginnen. Wir haben einen sauberen Docker-Container gebaut, um das Modell von äußeren Einflüssen zu isolieren, und eine Menge Lungenbilder von Kaggle heruntergeladen. Um mit den Bildern arbeiten zu können, haben wir sie untergeordnet und auf eine relevante und konsistente Auswahl eingegrenzt. Der Datensatz und die Trainingsumgebung waren bereit.
Das Training begann. Wir standen vor der Herausforderung des Übertrainings, wodurch sich das Modell Trainingsbilder merken konnte und infolgedessen neue Bilder in Zukunft nicht genau analysiert werden konnten. Unsere Lösung bestand darin, die Breite, Höhe, Körnigkeit und einige andere Parameter der Bilder leicht zu ändern. Wir haben auch Tensorboard eingeführt, um Trainingsmetriken zu überwachen.
In der letzten Phase haben wir das Modell zu Testzwecken in eine H5-Datei exportiert, ein Format, das häufig in Branchen vom Gesundheitswesen bis zur Luft- und Raumfahrt verwendet wird. Wir haben es manuell und automatisch mit voreingestellten Skripten getestet.
Präzision
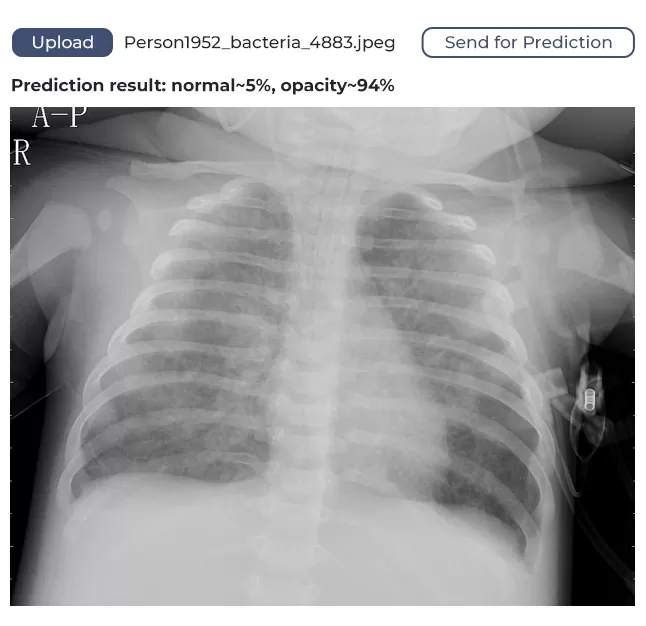
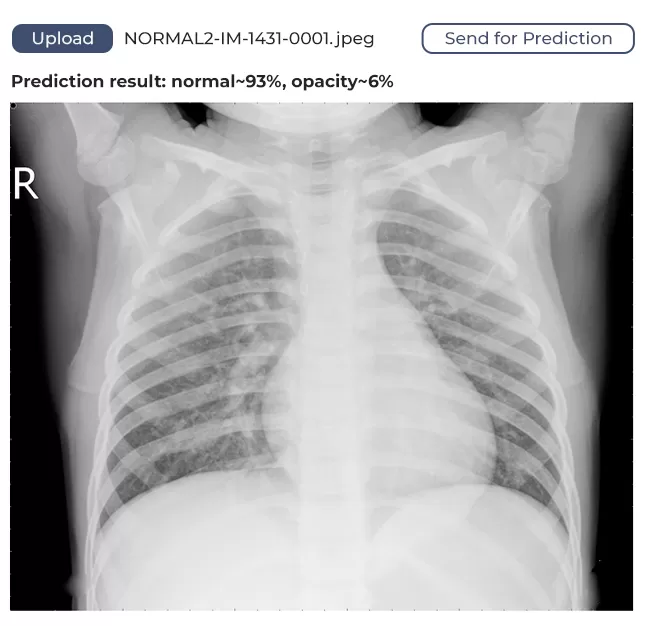
Das von uns entwickelte Modell hat eine Vertrauensspanne und verwendet eine binäre Identifizierung. Was bedeutet das? Das heißt, wenn der Algorithmus 80% der Lungen als nicht betroffen identifiziert, sagt er, dass die Lunge gesund ist. Wenn der Wert unter 80 % liegt, wird davon ausgegangen, dass die Lunge betroffen ist und ärztliche Hilfe erforderlich ist.
Wie es funktioniert
Der Nutzer öffnet die Webanwendung in seinem Browser, lädt ein Lungenbild hoch, sendet es an den Dienst und erhält Feedback. Das Feedback zeigt, ob die Lunge gesund ist oder ein Arzt sich das Bild ansehen sollte.
Ergebnis
Das von uns entwickelte Tool kann dazu beitragen, menschliche Fehler bei der Erkennung von Lungenentzündungen zu reduzieren. Dies ist besonders während der Pandemie sinnvoll, wenn die Ärzte überlastet sind und einige Krankheitszeichen übersehen könnten.
Wir können das Modell auch skalieren, um einige andere Krankheiten zu identifizieren. Das Herunterskalieren des Modells hilft dabei, es in andere Systeme zu integrieren, die Dinge zu beschleunigen und die gleichzeitige Analyse mehrerer Bilder zu ermöglichen.