







Ein Large Language Model (LLM) Gateway ist eine zentrale Schnittstelle, die den Zugriff auf mehrere Modelle über eine einzige API vereint. Es ermöglicht Unternehmen, neuronale Netzwerke von einem Ort aus zu verwalten und dabei eine einheitliche Sicherheit sowie Kostenkontrolle zu gewährleisten. Diese Gateways erhöhen die Ausfallsicherheit durch automatisches Failover und Request-Caching zur Optimierung der Budgets.
Da Unternehmen aktiv auf eine vollständig ausgebaute KI-Infrastruktur umstellen, sind LLM-Gateways geschäftskritisch geworden. Dieser Wandel treibt ein starkes Wachstum voran: Der Markt für LLM-Gateways erreichte 2026 ein Volumen von 2,76 Mrd. $ und soll bis 2030 auf 7,21 Mrd. $ anwachsen.
Was ist ein LLM-Gateway?
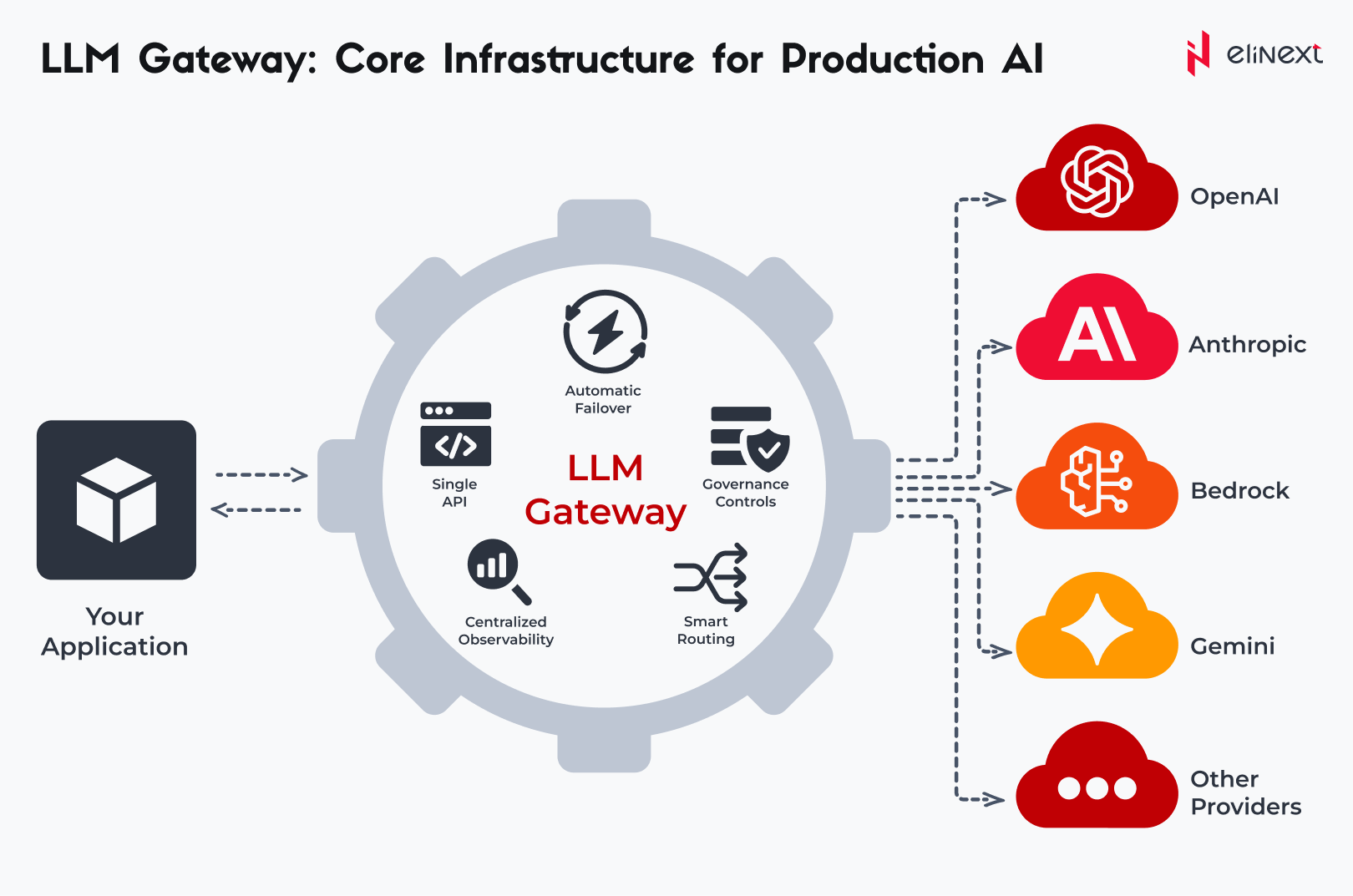
Ein LLM-Gateway ist eine intelligente Schicht zwischen Ihrer Anwendung und Dutzenden von Modellen neuronaler Netzwerke. Es übernimmt das Routing von Anfragen und das Caching von Antworten zur Budgetoptimierung sowie die Überwachung der Leistung in Echtzeit. Moderne LLM-Gateway-Architekturen ermöglichen zudem eine nahtlose Skalierung und eine einheitliche Steuerung aller KI-Komponenten.
Single API
Es handelt sich um eine einheitliche Schnittstelle zur Interaktion mit jedem neuronalen Netzwerk über standardisierte Anfragen. Sie beseitigt Vendor Lock-in und vereinfacht Ihre Architektur. Dadurch verdoppelt sich die Entwicklungsgeschwindigkeit, und die Migration auf ein neues Modell dauert nur wenige Minuten.
Automatisches Failover
Es handelt sich um einen Mechanismus für ein sofortiges Umschalten auf ein Backup-Modell oder eine andere Region, falls der primäre Anbieter ausfällt. Dadurch wird die Kontinuität kritischer Geschäftsprozesse sichergestellt. Die Verfügbarkeit von KI-Services erreicht 99,99 % und eliminiert Ausfallzeiten sowie Reputationsrisiken.
Smart Routing
Dies ist eine Funktion eines KI-Gateways, die Anfragen basierend auf Kosten, Latenz oder Qualität an das beste Modell weiterleitet. Sie reduziert Kosten durch den Einsatz günstigerer Modelle für einfache Aufgaben und gewährleistet durch automatisches Failover eine Verfügbarkeit von 99,9 %, was den gesamten ROI erhöht.
Zentralisierte Beobachtbarkeit
Es handelt sich um ein zentrales Dashboard zur Nachverfolgung aller Anfragen und des Tokenverbrauchs in Echtzeit. Centralized Observability hilft, den Ressourceneinsatz im gesamten Team zu kontrollieren und sorgt für vollständige Kostentransparenz sowie präzise Analysen der KI-Leistung.
Governance-Kontrollen
Es handelt sich um ein umfassendes Regelwerk für Zugriffskontrolle, PII-Filterung und regulatorische Compliance. Es hilft Ihnen, unternehmensweite Sicherheitsstandards einzuhalten und Datenlecks zu verhindern. Es gewährleistet einen sicheren Datenschutz und verhindert Budgetüberschreitungen.
Möchten Sie Ihre KI-Infrastruktur ohne unnötige Kosten oder Risiken skalieren? Entdecken Sie unsere KI-Dienstleistungen und implementieren Sie noch heute ein LLM-Gateway, um volle Kontrolle über Sicherheit, Budget und Leistung Ihrer neuronalen Netzwerke zu erhalten.
Top LLM-Gateways für 2026: Ein praktischer Vergleich
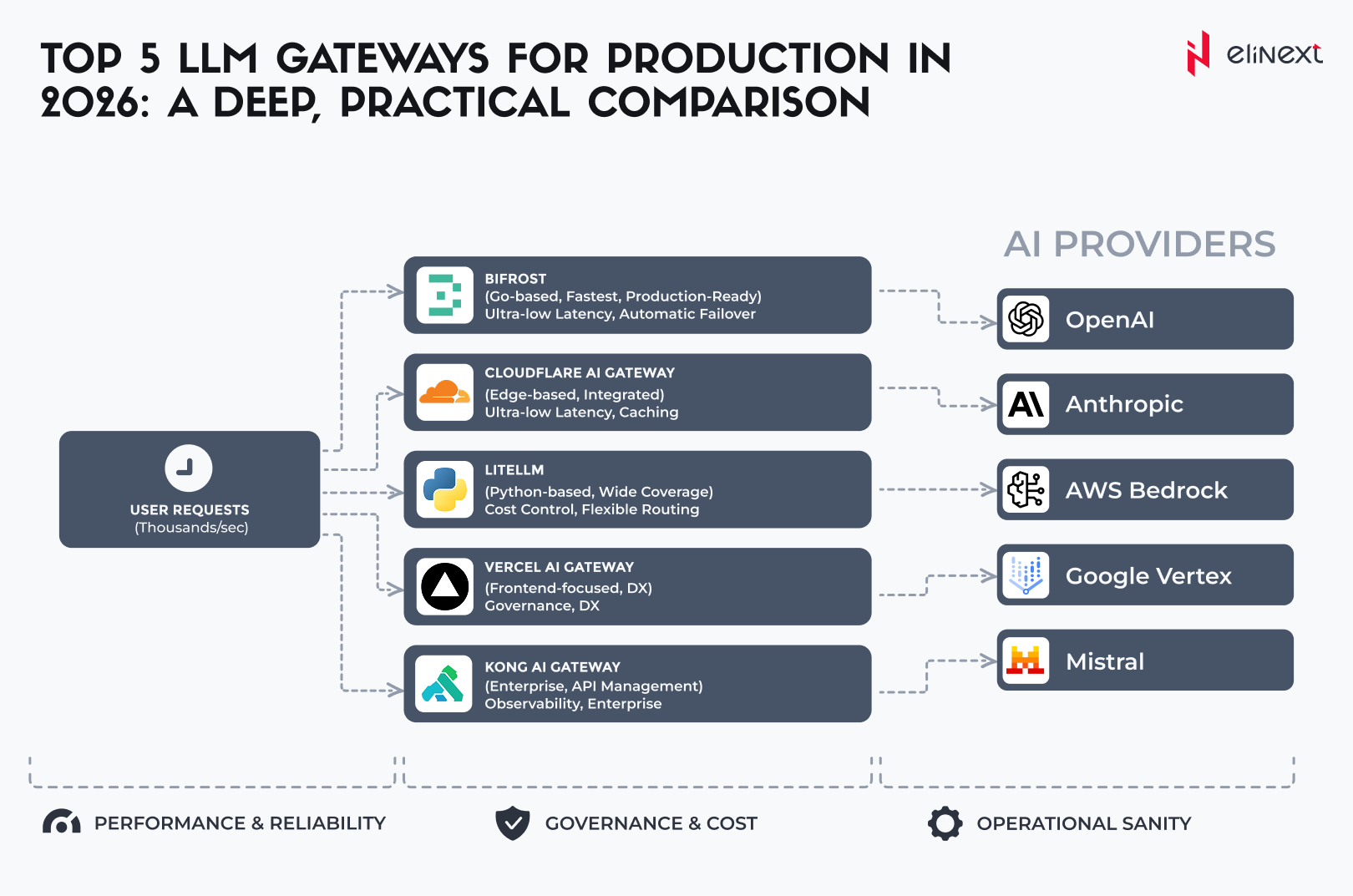
Bei der Auswahl eines LLM-Gateways sollten Sie die wirtschaftliche Effizienz Ihrer gesamten KI-Strategie berücksichtigen. Der Markt bietet Lösungen für jede Aufgabe, von leichtgewichtigen Open-Source-Tools bis hin zu leistungsstarken Enterprise-Plattformen. In diesem Abschnitt stellen wir die fünf führenden Anbieter vor, die sich aufgrund ihrer Zuverlässigkeit und Funktionalität als Goldstandard etabliert haben.
Cloudflare AI Gateway
Es handelt sich um eine globale Proxy-Schicht, die auf der Edge-Infrastruktur von Cloudflare basiert und für das Management sowie das Caching von KI-Anfragen entwickelt wurde. Sie bietet extrem niedrige Latenzzeiten und eine sofortige Bereitstellung für Unternehmen, die bereits das Cloudflare-Ökosystem nutzen. Das Gateway ermöglicht es Unternehmen, API-Kosten durch Edge-Caching erheblich zu reduzieren und die Sicherheit gegenüber schädlichen Prompts zu erhöhen, wodurch es ideal für Webanwendungen mit hohem Traffic ist.
Kong AI Gateway
Es handelt sich um eine Erweiterung des weltweit beliebtesten API-Gateways, die für große Unternehmen konzipiert wurde. Es vereinheitlicht die Governance von KI-Systemen und ermöglicht Teams, konsistente Sicherheits-, Logging- und Traffic-Richtlinien über alle LLMs hinweg anzuwenden. Es eignet sich besonders für Unternehmen mit komplexen Microservice-Architekturen und führt zu einer standardisierten KI-Nutzung sowie einem zentralisierten Management von Zugangsdaten, ohne bestehende Infrastruktur neu aufbauen zu müssen.
Bifrost
Es handelt sich um ein hochleistungsfähiges Gateway, das in Go entwickelt wurde und für geschäftskritische Anwendungen mit minimalem Overhead im Sub-Millisekundenbereich optimiert ist. Es überzeugt durch Smart Routing und automatisches Failover und gewährleistet selbst bei Ausfällen von Anbietern eine Verfügbarkeit von 99,99 %. Bifrost ist ideal für Entwickler von Echtzeit-KI-Agenten und Chatbots und bietet eine unvergleichliche Zuverlässigkeit sowie eine bis zu 50-mal schnellere Performance im Vergleich zu Python-basierten Alternativen.
LiteLLM
Es handelt sich um den branchenüblichen Open-Source-Proxy, der verschiedene Anbieterformate in ein einheitliches, OpenAI-kompatibles Format übersetzt. Er eliminiert Vendor Lock-in und vereinfacht die Kostenkontrolle für Start-ups und mittelgroße Teams. Viele Entwickler nutzen ihn zur Erstellung eigener LLM-Gateway-Anwendungen, was zu doppelt so schnellen Entwicklungszyklen und einer mühelosen Migration zwischen Modellen wie GPT-4 und Claude führt.
Vercel AI Gateway
Es handelt sich um ein spezialisiertes Tool für Frontend-Entwickler und moderne Webanwendungen innerhalb des Vercel-Ökosystems. Es bietet eine nahtlose Integration mit dem AI SDK sowie Observability und Caching für serverlose Umgebungen. Das Vercel AI Gateway eignet sich ideal für schnelles Prototyping und produktionsreife Next.js-Anwendungen und ermöglicht optimierte Deployments sowie eine transparente Echtzeit-Übersicht über den Tokenverbrauch pro Nutzer.
Wie wählt man das richtige LLM-Gateway aus?
Im Jahr 2026 ist die Wahl eines LLM-Gateways eine strategische Entscheidung im Kapitalmanagement. Etwa 37 % der Unternehmen nutzen inzwischen gleichzeitig mehr als fünf Modelle in der Produktion, wodurch Gateways notwendig werden, um eine fragmentierte Infrastruktur zu vermeiden.
Die Performance ist das entscheidende Unterscheidungsmerkmal: Führende Lösungen wie Bifrost erreichen Latenzen von nur 11 μs und sind damit 50-mal schneller als herkömmliche Tools. Priorisieren Sie semantisches Caching, um die Tokenkosten um 40 % zu senken, und stellen Sie integrierte Compliance sicher, da 45 % der KI-Nutzung außerhalb der IT-Kontrolle stattfinden. Die Effizienz in diesem Bereich bestimmt direkt den ROI Ihrer KI-Strategie.
„Die Integration von Dutzenden von LLMs führt zu Sicherheitschaos und unvorhersehbaren API-Kosten. Bei Elinext lösen wir dieses Problem, indem wir im Rahmen unserer LLM-Entwicklungsservices maßgeschneiderte Gateways mit fortschrittlicher Routing-Logik und Schutzmechanismen entwickeln. Dadurch wird eine fragmentierte KI-Infrastruktur in ein steuerbares Asset verwandelt, operative Kosten werden um 30 % gesenkt und die vollständige Einhaltung unternehmensweiter Standards für die Datenverarbeitung sichergestellt.“ – Aliaksei Druzik, Experte für KI- und ML-Transformation
Entdecken Sie LLM-Lösungen von Elinext
Elinext transformiert fragmentierte Modelle neuronaler Netzwerke durch unsere individuellen LLM-Gateway-Anwendungen in robuste Geschäftssysteme. Unsere Lösungen bieten intelligentes Routing, semantisches Caching und tiefgehende Analysen zur Kontrolle von Kosten und Sicherheit. Mit unseren Services in der Entwicklung von Machine-Learning-Lösungen und generativer KI-Lösungen bieten wir umfassende Unterstützung für die Modernisierung von Enterprise-KI.
Machen Sie Ihre Infrastruktur zukunftssicher mit professionellen KI-Integrationsservices! Kontaktieren Sie die Experten von Elinext, um eine skalierbare Strategie für die Implementierung von LLM-Gateway-Anwendungen in Ihrem Unternehmen zu entwickeln.
Fazit
Im Jahr 2026 ist eine LLM-Gateway-Architektur die Grundlage für das Überleben von Unternehmen in der Datenökonomie. Die Zentralisierung des Modellzugriffs ermöglicht es Unternehmen, agil zu bleiben, ohne Sicherheit oder Budget zu gefährden. Ein richtig gewähltes Gateway verwandelt experimentelle KI in ein stabiles, industrietaugliches Werkzeug mit vorhersehbaren Kosten. Während der Markt weiter wächst, ist die Integration solcher Lösungen der schnellste Weg zu technologischer Führerschaft und operativer Exzellenz.
LLM-Gateways: Begriffe erklärt
Multi-Provider Routing
Automatische Weiterleitung von Anfragen zwischen verschiedenen Anbietern (OpenAI, Anthropic und anderen), um Kosten, Antwortgeschwindigkeit und Generierungsqualität in Echtzeit zu optimieren.
Failover / Fallbacks
Ein Mechanismus für das sofortige Umschalten auf ein Backup-Modell im Falle eines Ausfalls des primären Modells. Er garantiert einen unterbrechungsfreien Betrieb von KI-Services selbst bei technischen Problemen auf Seiten des Anbieters.
Semantic Caching
Speicherung von Antworten basierend auf ihrer Bedeutung und nicht nur auf exakten Textübereinstimmungen. Es liefert fertige Ergebnisse für ähnliche Anfragen zurück, reduziert die Tokenkosten drastisch und minimiert die Latenz.
Observability / Telemetrie
Erfassung und Analyse detaillierter Metriken (Logs, Antwortzeiten, Tokens usw.) für alle Anfragen. Sie bietet vollständige Transparenz über die Leistung der KI-Infrastruktur und vereinfacht das Debugging des Systems.
Guardrails
Softwarebasierte Filter, die Prompts und Antworten validieren. Sie schützen vor Datenlecks, Halluzinationen und toxischen Inhalten und gewährleisten eine ethische, sichere und konforme Nutzung von LLMs in der Produktion.
Unified API
Eine standardisierte Schnittstelle zur Interaktion mit allen Arten von Sprachmodellen. Sie macht es überflüssig, Code beim Wechsel von Anbietern oder bei der Aktualisierung von Modellversionen neu zu schreiben, und sorgt für eine nahtlose Integration.
Rate Limiting
Ein Tool zur Steuerung der Häufigkeit von API-Anfragen. Es verhindert Systemüberlastungen, schützt vor Missbrauch und stellt sicher, dass der Ressourcenverbrauch innerhalb festgelegter Budget- und technischer Grenzen bleibt.
Edge Deployment
Die Platzierung von Gateway-Kapazitäten auf Knoten so nah wie möglich am Nutzer. Dadurch wird die Netzwerklatenz minimiert und nahezu sofortige Antworten für KI-Anwendungen weltweit gewährleistet.
Provider-Agnostic
Ein anbieterneutraler architektonischer Ansatz. Er ermöglicht einen nahtlosen Wechsel zwischen Modellen, um die besten Marktbedingungen und Leistungen zu nutzen, ohne technische Schulden zu verursachen.
Token Budgeting
Ein System aus Quoten und Token-Nutzungsgrenzen für verschiedene Abteilungen oder Projekte. Es ermöglicht eine präzise Kostenprognose und verhindert unerwartete Budgetüberschreitungen.
FAQ
Was ist ein LLM-Gateway?
Ein LLM-Gateway ist eine zentrale Proxy-Schicht, die Anwendungen über eine einzige Schnittstelle mit mehreren KI-Modellen verbindet. Es wird zur Verwaltung von Traffic, Sicherheit und Kosten eingesetzt. Unternehmen nutzen es, um die Architektur zu vereinfachen und Vendor Lock-in zu vermeiden.
Wie wähle ich das richtige LLM-Gateway aus?
Die richtige Wahl basiert auf spezifischen Anforderungen wie Latenz, Sicherheits-Compliance und Unterstützung der bevorzugten Modelle. Ziel ist es, die KI-Infrastruktur mit den Geschäftszielen in Einklang zu bringen. Unternehmen setzen darauf, um Skalierbarkeit und Zuverlässigkeit sicherzustellen
Sind LLM-Gateways teuer?
Es gibt verschiedene Preismodelle, die von kostenlosen Open-Source-Versionen bis hin zu kostenpflichtigen Enterprise-Plattformen reichen. Die Kosten bestehen hauptsächlich aus architektonischer Entwicklung, Infrastruktur-Overhead und der Wartung von Sicherheits-Guardrails.
Kann ich mehrere Gateways gleichzeitig nutzen?
Ja, Sie können mehrere Gateways für verschiedene Regionen oder spezifische Anforderungen einzelner Abteilungen einsetzen. Dies verhindert Single Points of Failure, verbessert die globale Latenz und ermöglicht es, gleichzeitig die besten Funktionen verschiedener Anbieter in unterschiedlichen Regionen zu nutzen.
Funktionieren Gateways mit allen LLMs?
Die meisten Gateways funktionieren mit nahezu jedem LLM über eine Unified API, indem sie unterschiedliche Formate in einen einheitlichen Standard übersetzen. Sie unterstützen große Anbieter wie OpenAI und Anthropic sowie lokale Modelle (Llama, Mistral) über Tools wie vLLM oder Ollama.
Wie verbessern LLM-Gateways die Kosteneffizienz?
Sie verfügen über integrierte Funktionen wie semantisches Caching und Smart Routing, die unnötigen Tokenverbrauch reduzieren. LLM-Gateway-Architekturen werden eingesetzt, um übermäßige Ausgaben für teure Modelle zu vermeiden. Unternehmen berichten von bis zu 40 % geringeren operativen KI-Kosten.
Werden LLM-Gateways direkte API-Aufrufe ersetzen?
Ja, LLM-Gateways ersetzen direkte API-Aufrufe zunehmend als Standard-Control-Plane für KI. Direkte Aufrufe gelten heute als technischer Ballast, während Gateways einen einheitlichen Proxy für nahtlosen Modellwechsel, automatisches Failover und zentrale Sicherheitskontrolle bieten.
