







Die Echtzeit-Stream-Verarbeitung ist zu einem entscheidenden Aspekt geworden, um Live-Datenströme zu verwalten und sofortige Informationen zu erhalten. Kafka, eine robuste verteilte Streaming-Plattform, bildet in Kombination mit Java ein leistungsstarkes Duo für den Aufbau skalierbarer und effizienter Echtzeit-Stream-Verarbeitungsanwendungen.
In diesem Artikel werden wir uns die Grundlagen zum Erstellen einer solchen Anwendung mit Kafka und Java ansehen. Wir werden eine klare Struktur, praktische Codebeispiele und eine Erkundung der beteiligten Feinheiten betrachten.
Überblick über Apache Kafka
Lassen Sie uns die Essenz der Echtzeit-Stream-Verarbeitung betrachten. Echtzeit-Stream-Verarbeitung basiert auf der Verarbeitung und Analyse von Daten, während sie generiert oder aufgenommen werden, und ermöglicht eine sofortige Schätzung und Reaktionen.
Apache Kafka, ursprünglich von LinkedIn entwickelt und später als Projekt der Apache Software Foundation Open Source gemacht, fungiert als verteilte Ereignis-Streaming-Plattform. Im Gegensatz zu traditionellen Nachrichtensystemen zeichnet sich Kafka durch die Behandlung von Datenströmen in einer fehlertoleranten und skalierbaren Weise aus. Es ist besonders für Szenarien konzipiert, in denen Daten in Echtzeit verarbeitet werden müssen, was es zu einer entscheidenden Technologie für moderne datengesteuerte Anwendungen macht.
Kafka, ein Open-Source-verteilter Datenspeicher, zeichnet sich als Ereignis-Streaming-Plattform aus und ist somit eine ideale Wahl für die Entwicklung von Echtzeit-Anwendungen.
Also, die wahrscheinlichste Frage lautet: Warum Kafka? Die Architektur von Kafka, basierend auf verteilten Commit-Logs, garantiert Fehlertoleranz, Skalierbarkeit und Zuverlässigkeit. Seine Fähigkeit, Datenströme im großen Maßstab mit einer latenzarmen Verarbeitung zu verwalten, macht es zum Werkzeug der Wahl in verschiedenen Branchen, von Finanzwesen bis E-Commerce.
Anwendungsfälle von Apache Kafka
Protokollaggregation:
Kafka wird weit verbreitet eingesetzt, um Protokolldaten aus verschiedenen Anwendungen und Systemen zu aggregieren und bietet eine zentrale Plattform für Überwachung und Analyse.
Event Sourcing:
In ereignisgesteuerten Architekturen fungiert Kafka als zuverlässiger Ereignisspeicher und ermöglicht es Anwendungen, einen vollständigen Satz von Ereignissen für Prüfungen und Analysen zu führen.
Kommunikation zwischen Microservices:
Kafka dient als Kommunikationsrückgrat für Microservices und erleichtert den Austausch von Nachrichten zwischen verschiedenen Diensten auf eine skalierbare und fehlertolerante Weise.
Datenintegration:
Kafka vereinfacht die Integration unterschiedlicher Datenquellen und ermöglicht einen Echtzeitdatenfluss zwischen Anwendungen und Systemen.
Wichtige Komponenten von Apache Kafka
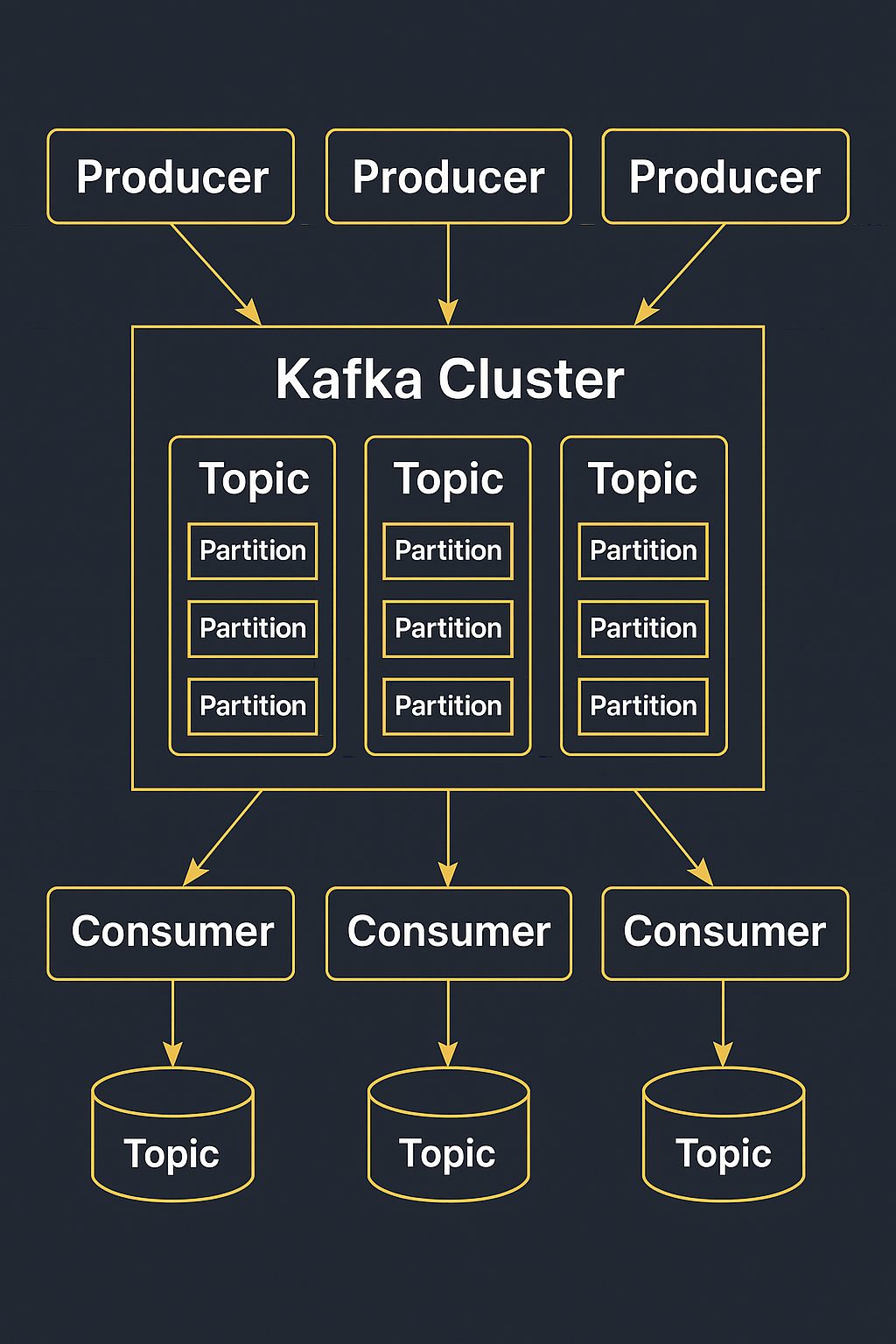
1. Produzent: Im Kafka-Ökosystem ist ein Produzent dafür verantwortlich, Datensätze an ein oder mehrere Kafka-Themen zu veröffentlichen. Das Thema ist die wichtigste Abstraktion, die von Kafka bereitgestellt wird: Es handelt sich um einen Kategorie- oder Feed-Namen, unter dem Daten von Produzenten veröffentlicht werden.
2. Broker: Kafka läuft in einer verteilten Umgebung mit einem Cluster von Brokern. Jeder Broker speichert die Daten und bedient Clients. Die verteilte Natur der Broker bietet Fehlertoleranz und Skalierbarkeit.
3. Konsument: Verbraucher abonnieren ein oder mehrere Themen und verarbeiten den Strom von Datensätzen, die diesen Themen zugeordnet sind. Kafka-Verbraucher können Teil einer Verbrauchergruppe sein, was parallele Verarbeitung von Daten für verbesserte Leistung ermöglicht.
4. Thema: Ein Thema ist eine Kategorie oder ein Name des Kanals, in dem Datensätze veröffentlicht werden. Themen ermöglichen es, Datenströme zu organisieren und zu segmentieren.
5. Zookeeper: Obwohl Kafka für seine verteilte Architektur bekannt ist, verlässt es sich auf Apache ZooKeeper, um die Kafka-Broker im Cluster zu verwalten und zu koordinieren.
Bevor Sie in die Anwendungsentwicklung eintauchen, ist es wichtig, Apache Kafka einzurichten. Im Folgenden finden Sie eine schrittweise Anleitung, um Ihnen den Einstieg zu erleichtern:
A. Kafka-Installation
1. Kafka herunterladen: Besuchen Sie die offizielle Website Apache Kafka Downloads und laden Sie das Kafka-Verteilungspaket herunter.
2. Kafka extrahieren: Sobald der Download abgeschlossen ist, extrahieren Sie das heruntergeladene Archiv.
B. Zookeeper initialisieren

C. Starten des Kafka-Servers

Lassen Sie uns jetzt mit dem Aufbau unserer Echtzeit-Stream-Verarbeitungsanwendung mit einem Kafka-Produzenten in Java beginnen.
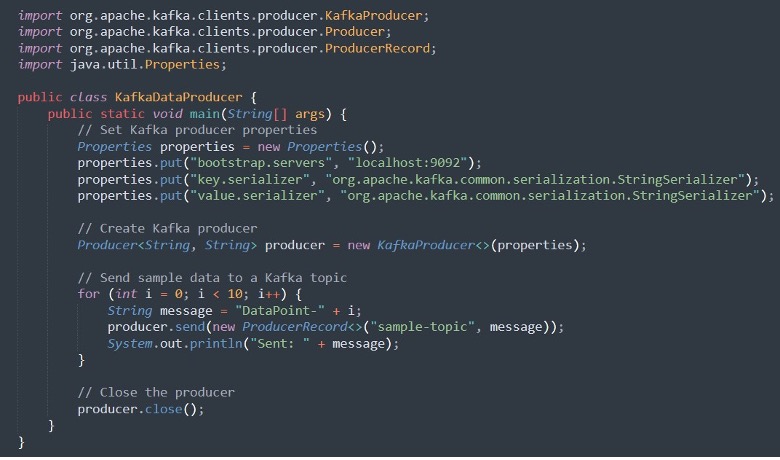
Dieses Java-Programm richtet einen Kafka-Produzenten ein, konfiguriert Verbindungseigenschaften und sendet Beispieldaten an ein Kafka-Thema.
