







Manchmal kann die Datenbankmigration zu einer Herausforderung werden. Die Tabellen sind groß, die Last ist hoch, HDD-Speicherplatz ist teuer und die Ausfallzeit sollte so kurz wie möglich sein. Das Elinext-Team hat kürzlich im Rahmen eines unserer Ruby-on-Rails-Projekte das Problem untersucht und eine flexible Datenmigrationsstrategie entwickelt.
Die Herausforderung begann mit der Migration der hochbelasteten Tabelle, die mehr als 2 Milliarden Zeilen enthielt, bei der wir den Datentyp für einen Primärschlüssel der Tabelle ändern mussten. Das ultimative Ziel des Kunden war es, eine Lösung zu entwickeln, die es ermöglicht, beliebige Änderungen an den Tabellen vorzunehmen, Daten dynamisch zu modifizieren, den vom Datenbank belegten HDD-Speicherplatz zu überwachen und den Migrationsprozess zu protokollieren.
Mit diesem Ziel vor Augen haben wir folgende Anforderungen an die Datenbankmigration festgelegt:
- Vollständige Zugänglichkeit zu allen Daten während des gesamten Migrationsprozesses für Lese-, Schreib-, Lösch- und Aktualisierungsvorgänge.
- Kürzeste mögliche Ausfallzeit.
- Minimierung von Daten-Duplizierung (keine Datenbankkopien oder vollständige Kopien der migrierten Tabelle).
- Migration wird aus dem Web-Framework ausgelöst und gesteuert.
- Keine Änderungen am vorhandenen Framework-Code – nur einige Ergänzungen im Zusammenhang mit der Auslösung und Überwachung der Migration. Keine zusätzlichen Bereitstellungen während des gesamten Prozesses erforderlich.
In dem Bestreben, eine Lösung zu finden, haben wir mehrere Optionen ausprobiert, aber alle blockierten die Tabelle oder die Datenbank länger als wir es uns leisten konnten. Also haben wir uns entschieden, einen anderen Ansatz zu versuchen. Die grundlegende Idee war es, drei Tabellen zu haben und die Daten zwischen ihnen im Hintergrund ohne Duplikation zu verschieben. Schauen wir mal, was wir bekommen haben:
- Die erste Tabelle (‚old‘) ist die eigentliche alte Tabelle mit vielen Zeilen.
- Die zweite Tabelle (’new‘) kopiert die Struktur der ‚old‘ Tabelle, hat aber die erforderlichen Modifikationen (bigint Primärschlüssel in unserem Fall). Diese Tabelle ist das Ergebnis, sie speichert die Daten und bleibt im System, nachdem die Migration abgeschlossen ist.
- Die dritte Tabelle (‚temp‘) wird verwendet, um laufende Einfügungen, Aktualisierungen und Löschungen, die durch Benutzer verursacht werden, zu verarbeiten. Ihre Struktur kopiert die ’new‘ Tabelle.
Der eigentliche Hintergrund-Job verschiebt (nicht kopiert) Daten von den ‚old‘ und ‚temp‘ Tabellen zur ’new‘ Tabelle. Dadurch wird die ’new‘ Tabelle für Einfügungen, die von Benutzern kommen (Web-Framework-Seite), sehr langsam. Deshalb verwenden wir die ‚temp‘ Tabelle, um die laufenden Einfügungen vom Web-Server zu bedienen. Die ‚temp‘ Tabelle wird nicht von der Migration geladen, weshalb die Gesamtleistung auf einem guten Niveau bleibt.
Zusätzlich werden SQL-Ansichten und Funktionen verwendet, um das Verhalten der alten Tabelle für das Web-Framework (RoR in unserem Fall) zu emulieren. Die Ansichten fungieren als Adapter zwischen dem Web-Framework (das so tut, als ob es immer noch mit der alten Tabelle kommuniziert) und den tatsächlichen drei Tabellen in der Datenbank.
Nachfolgend finden Sie einige PostgreSQL-Code, den wir verwendet haben, um alle erforderlichen Tabellen, Funktionen und Ansichten zu erstellen. Dieser Code wurde von einer Rake-Task manuell initiiert, sobald wir beschlossen haben, die Migration zu starten. Es versteht sich von selbst, dass Transaktionen dort verwendet werden sollten, wo sie zur Sicherheit des Flusses beitragen.
-
Erstellen Sie die neue Tabelle, ändern Sie sie und benennen Sie die alte Tabelle um:


-
Erstellen Sie die Ansicht, um das Verhalten der Tabelle „cars“ bei SELECT-Abfragen des Web-Frameworks zu emulieren:


-
Setzt den nächsten id-Wert für „cars“ auf die aktuelle cars id-Sequenz.


-
Erstellen Sie eine Funktion, die die vom Web-Framework kommenden Einfüge-, Aktualisierungs- und Löschvorgänge verarbeitet:


-
Erstellen Sie den Trigger, um die Aufrufe der Tabelle „Autos“ an die oben erstellte Funktion umzuleiten.


Wenn dieser Code initiiert wird, sollte das Framework wie gewohnt funktionieren. Der SQL-Server schreibt jedoch die neuen Daten in die „temp“-Tabelle mit einer ID, die direkt nach der letzten ID in der alten Tabelle beginnt. Und die SELECT-Aufrufe sammeln Elemente aus den drei Tabellen.
Unser nächster Schritt ist die eigentliche Datenmigration. Zu diesem Zweck erstellen wir einen Hintergrund-Job. Dieser kann manuell gestartet werden, durch eine Zeitplanung, direkt nach der Initiierung des obigen SQL-Codes usw. Die Hauptaufgabe dieses Jobs besteht darin, Daten von den Tabellen „old“ und „temp“ in eine neue Tabelle mit den gewünschten Änderungen zu verschieben. Um den Prozess zu optimieren, schlägt unser Team vor, eine gespeicherte Funktion zu verwenden und diese aus dem Job aufzurufen (anstatt immer wieder den gesamten SQL-Code auf der Framework-Seite zu bilden). Hier ist ein Beispiel für eine solche Funktion:

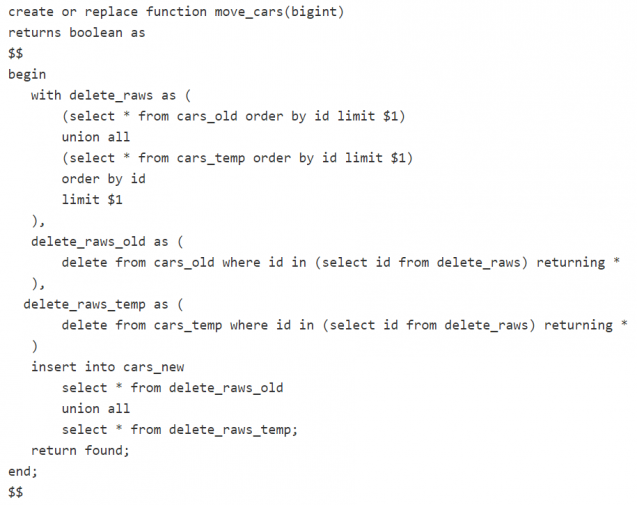
Diese Funktion kann von einem Job wie folgt aufgerufen werden: SELECT move_cars(10000);
Es besteht die Möglichkeit, beliebige zusätzliche Logik zum Job hinzuzufügen. Zum Beispiel haben wir einmal VACUUM CLEAN und ANALYZE aufgerufen, um die Datenbankgröße zu optimieren. Wir haben auch einige Protokollierungen hinzugefügt, um den Fortschritt zu verfolgen.
Wenn die Migration abgeschlossen ist, ist es an der Zeit aufzuräumen. Wir müssen die Ansicht löschen, die Funktionen löschen und die Tabellen austauschen. Die folgenden Aktionen wurden durchgeführt:
- Eine Transaktion öffnen.
- Die Sync-Funktion ein letztes Mal aufrufen, um sicherzustellen, dass keine Daten verloren gehen. (‚SELECT move_cars(10000000);‘)
- Den Austausch- und Aufräumcode ausführen.
- Die Transaktion schließen.
Und hier ist der Austausch- und Aufräumcode:


