







Was ist Föderiertes Lernen?
Föderiertes Lernen (FL) ist ein maschinelles Lernverfahren, bei dem ein Modell auf mehreren dezentralen Geräten oder Servern, die lokale Datenproben enthalten, trainiert wird, ohne diese auszutauschen.
Dies steht im Gegensatz zu traditionellen zentralisierten maschinellen Lerntechniken, bei denen alle Daten auf einen Server hochgeladen werden. FL speichert Daten auf dem Gerät und entkoppelt so die Fähigkeit, maschinelles Lernen durchzuführen, von der Notwendigkeit, die Daten in der Cloud zu speichern. In diesem Artikel werden wir untersuchen, wie man föderiertes Lernen implementiert.
Vorteile des Föderierten Lernens
- Datenschutz: Durch die Speicherung von Daten auf lokalen Geräten stellt FL sicher, dass persönliche und sensible Informationen privat und sicher bleiben.
- Reduzierte Latenz: Lokales Training von Modellen reduziert den Bedarf an umfangreichen Datentransfers, was die Latenz verringert.
- Skalierbarkeit: FL ermöglicht die Einbeziehung einer großen Anzahl von Geräten, die alle zum Trainingsprozess beitragen, ohne einen zentralen Server zu überlasten.
- Personalisierung: Modelle können für einzelne Benutzer oder spezifische Umgebungen angepasst werden, wodurch die Relevanz und Genauigkeit der Vorhersagen erhöht wird.
Wie Föderiertes Lernen funktioniert
Föderiertes Lernen ist besonders vorteilhaft für datenschutzsensible Anwendungen wie Gesundheit, Finanzen und persönliche Geräte, bei denen das Teilen von Rohdaten unpraktisch oder gesetzlich eingeschränkt ist. Die grundlegenden Schritte im föderierten Lernen sind:
- Initialisierung: Der Server initialisiert das Modell.
- Auswahl: Eine Untergruppe von Geräten wird ausgewählt, um am Training teilzunehmen.
- Konfiguration: Geräte konfigurieren ihre lokale Trainingsumgebung.
- Lokales Training: Jedes Gerät trainiert das Modell mit seinen lokalen Daten.
- Aggregation: Der Server sammelt die lokal trainierten Modelle und aggregiert sie.
- Aktualisierung: Das aggregierte Modell wird zurück an die Geräte verteilt.
Föderiertes Lernen funktioniert, indem ein generisches Basismodell auf einem zentralen Server beibehalten wird. Dieses Modell wird kopiert und an Client-Geräte verteilt, die diese Kopien dann mit ihren lokalen Daten trainieren. Infolgedessen werden die Modelle auf den einzelnen Geräten immer stärker personalisiert, was die Benutzererfahrung verbessert.
In der anschließenden Phase werden Aktualisierungen (Modellparameter) von den lokal trainierten Modellen unter Verwendung sicherer Aggregationstechniken zurück an den zentralen Server gesendet. Der zentrale Server kombiniert und mittelt diese Aktualisierungen, um neue Erkenntnisse zu gewinnen. Da die Daten aus verschiedenen Quellen stammen, kann das Modell allgemeiner anwendbar werden.
Sobald das zentrale Modell mit den neuen Parametern aktualisiert wurde, wird es für eine weitere Trainingsrunde wieder an die Client-Geräte verteilt. Mit jedem Zyklus sammeln die Modelle ein breiteres Spektrum an Informationen und verbessern sich kontinuierlich, ohne die Privatsphäre zu gefährden.
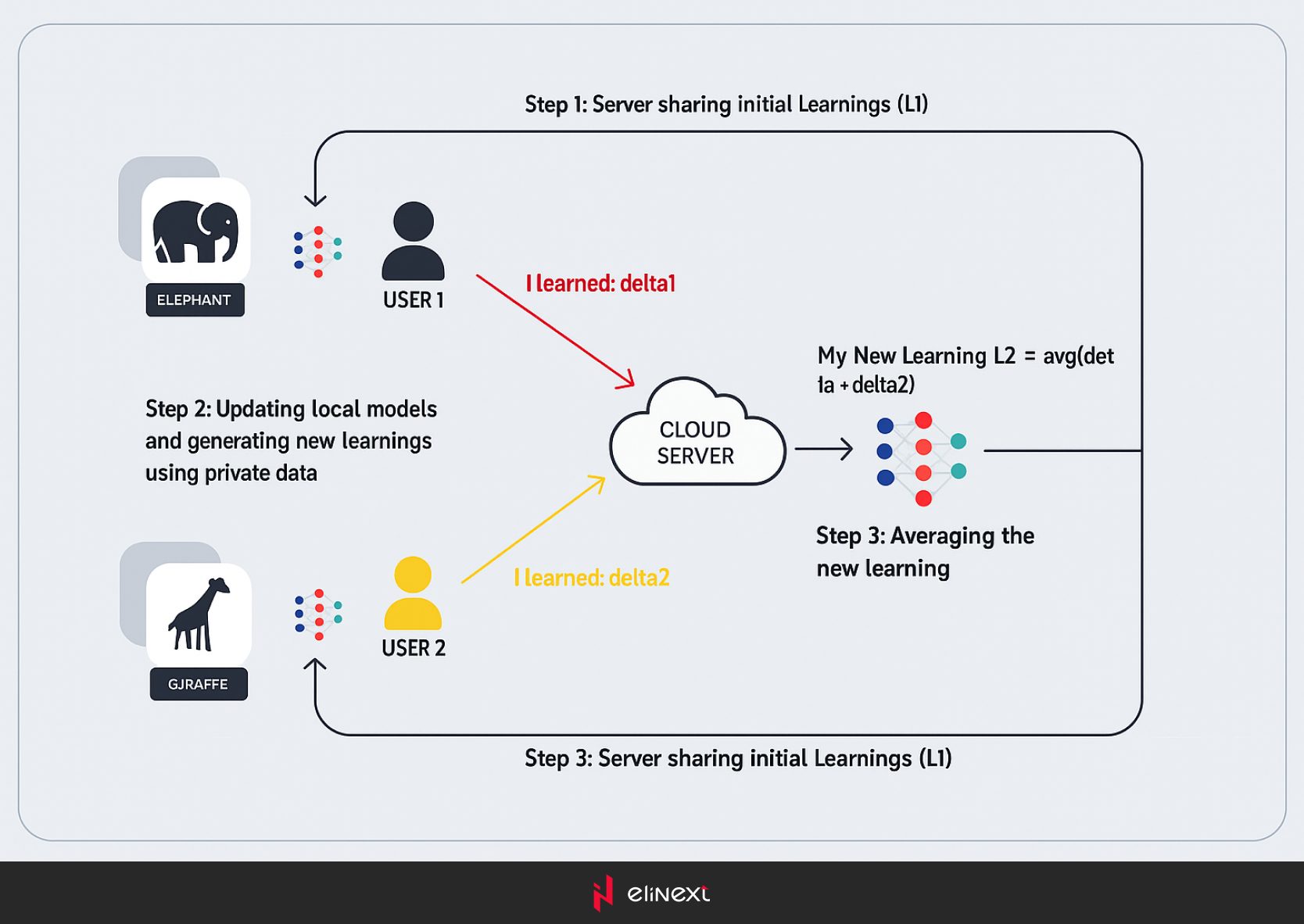
Föderierte Lernstrategien
Zentralisiertes Föderiertes Lernen
Zentralisiertes föderiertes Lernen stützt sich auf einen zentralen Server, um den Prozess zu koordinieren. Dieser Server wählt die Client-Geräte aus und sammelt während des Trainings Modell-Updates. Die Kommunikation erfolgt ausschließlich zwischen dem zentralen Server und den einzelnen Edge-Geräten.
Obwohl dieser Ansatz unkompliziert ist und genaue Modelle erzeugen kann, stellt er ein Engpassproblem dar. Netzwerkausfälle am zentralen Server können den gesamten Prozess unterbrechen, was zu möglichen Ausfallzeiten und Ineffizienzen führen kann.
Dezentralisiertes Föderiertes Lernen
Dezentralisiertes föderiertes Lernen erfordert keinen zentralen Server. Stattdessen werden Modell-Updates direkt zwischen miteinander verbundenen Edge-Geräten ausgetauscht. Das endgültige Modell wird durch die Aggregation der lokalen Updates dieser Geräte erhalten.
Dieser Ansatz verringert das Risiko eines einzelnen Ausfallpunkts. Allerdings hängt die Genauigkeit des Modells stark von der Netzwerktopologie der Edge-Geräte ab.
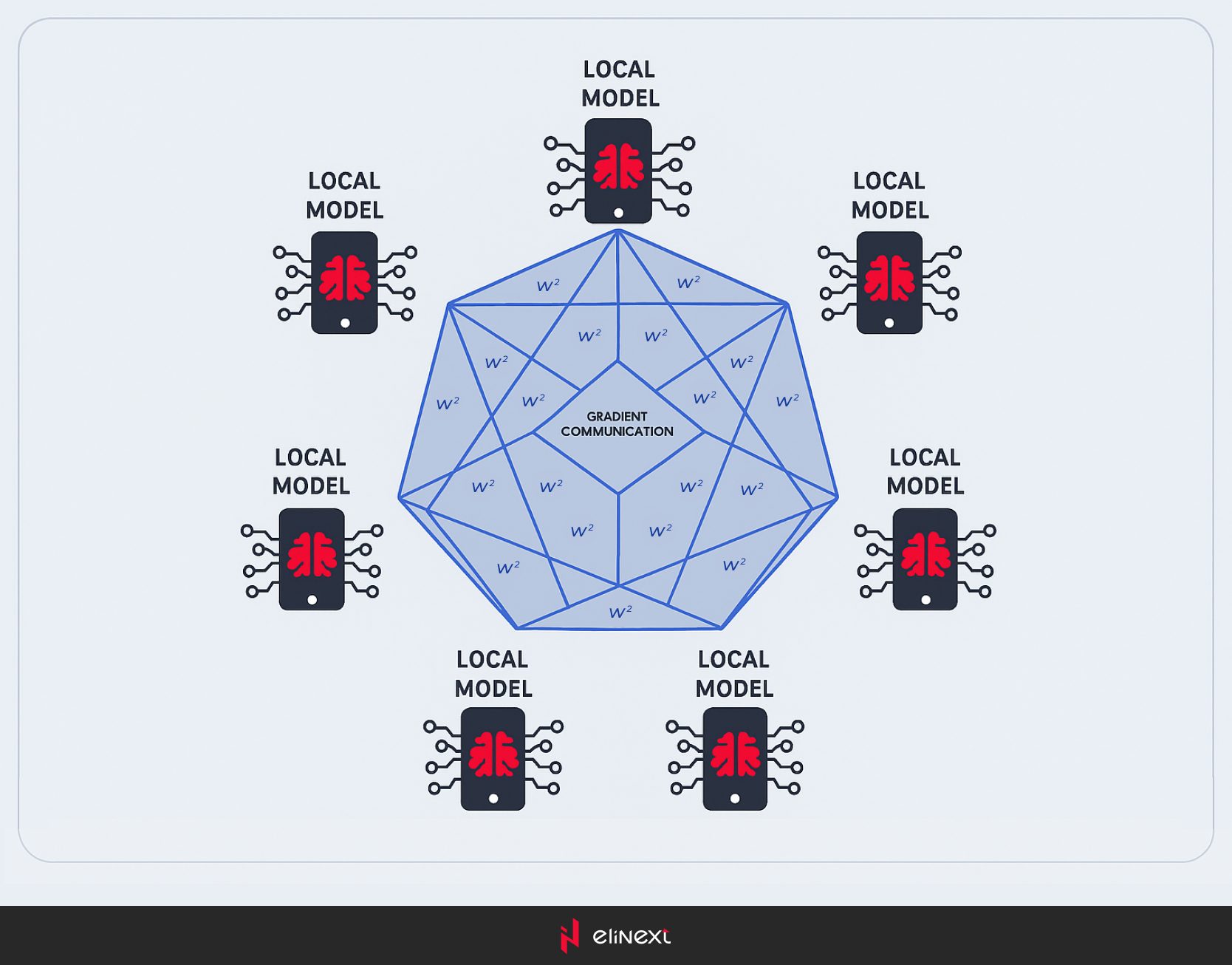
Heterogenes Föderiertes Lernen
Heterogenes föderiertes Lernen umfasst eine Vielzahl von Clients, wie Mobiltelefone, Computer und IoT (Internet of Things)-Geräte. Diese Geräte können sich erheblich in Bezug auf Hardware, Software, Rechenleistung und Datentypen unterscheiden.
HeteroFL wurde entwickelt, um die Einschränkungen traditioneller föderierter Lernstrategien zu überwinden, die oft davon ausgehen, dass lokale Modelle dem zentralen Modell ähnlich sind. In Wirklichkeit ist dies selten der Fall. HeteroFL ermöglicht es, ein einziges globales Modell zu trainieren, indem Erkenntnisse aus verschiedenen lokalen Modellen kombiniert werden, wodurch die Vielfalt der Client-Geräte berücksichtigt wird.
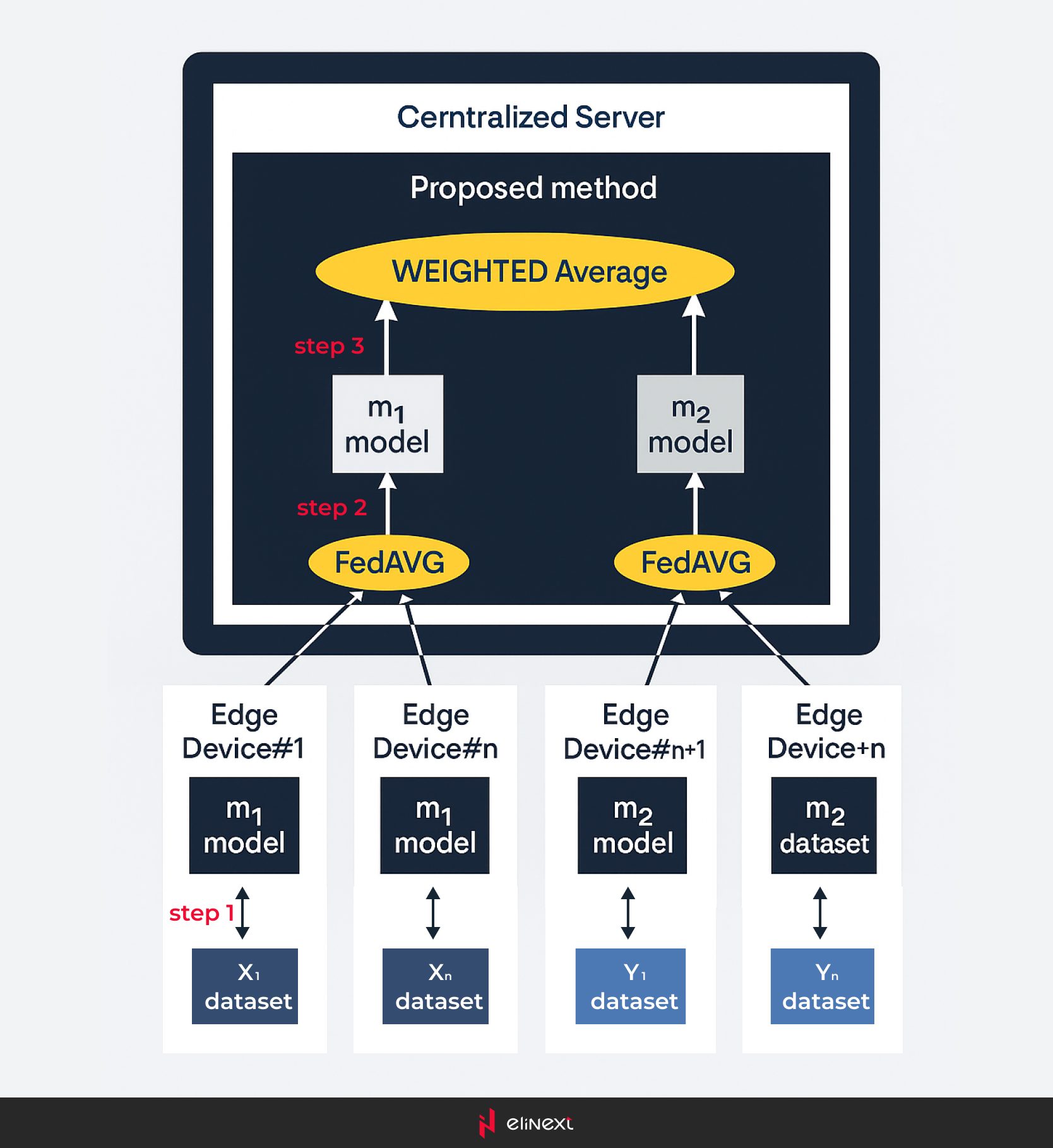
Föderierte Lern-Frameworks
Mit dem Fortschritt der Forschung im Bereich der Computer Vision durch großskalige Convolutional Neural Networks (CNNs) und dichte Transformer-Modelle ist ein Mangel an Werkzeugen und Methoden für deren Implementierung in einer föderierten Umgebung deutlich geworden.
Das FedCV-Framework zielt darauf ab, diese Lücke zu schließen und den Übergang von der Forschung zur realen Implementierung von föderierten Lernalgorithmen zu erleichtern.
FedCV ist eine umfassende Bibliothek, die für föderiertes Lernen in Anwendungen der Computer Vision entwickelt wurde, einschließlich Bildsegmentierung, Bildklassifizierung und Objekterkennung. Es bietet einfachen Zugang zu verschiedenen Datensätzen und Modellen über benutzerfreundliche APIs. Das Framework besteht aus drei Hauptmodulen: Computer Vision Applications Layer, High-Level API und Low-Level API. Lassen Sie uns die Beiträge jedes dieser Module genauer betrachten.
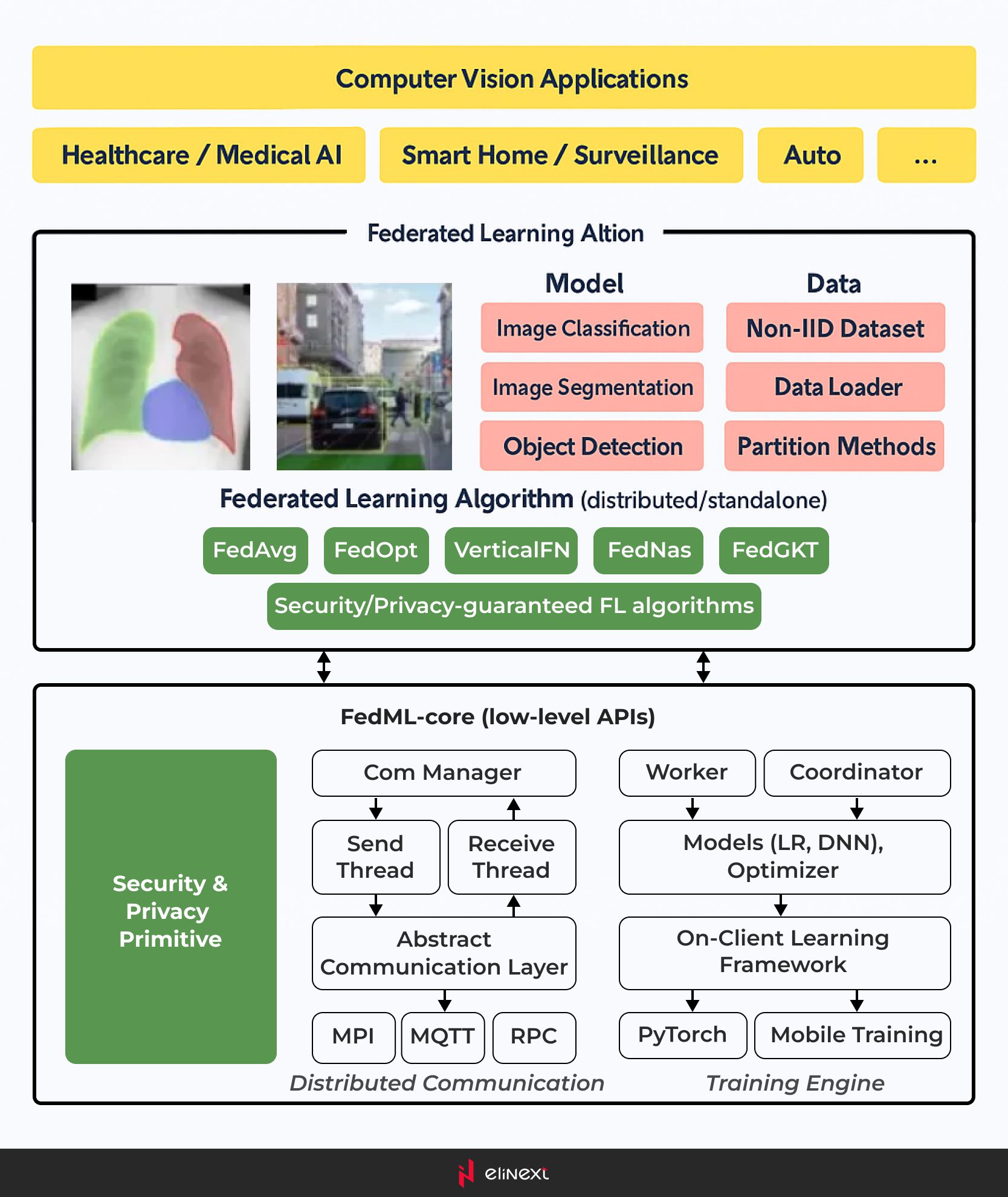
Die High-Level API
Die High-Level API in FedCV bietet Modelle für Computer Vision-Aufgaben wie Bildsegmentierung, Bildklassifizierung und Objekterkennung. Benutzer können vorhandene Daten-Loader und Datenpartitionierungsschemata verwenden oder ihre eigenen nicht-i.i.d. (nicht identisch und unabhängig verteilte) Datensätze erstellen, um die Robustheit von föderierten Lernmethoden zu testen und reale Datencharakteristika widerzuspiegeln.
Diese API umfasst auch Implementierungen von hochmodernen föderierten Lernalgorithmen wie FedAvg, FedNAS und anderen. Mit Unterstützung für verteiltes Training über mehrere GPUs können diese Algorithmen effizient trainiert werden. Darüber hinaus verbessern neuartige verteilte Rechenstrategien den Trainingsprozess.
Das benutzerorientierte Design der API ermöglicht eine einfache Implementierung und flexible Interaktionen zwischen Clients und Workern.
Die Low-Level API
Die Low-Level API konzentriert sich auf verbesserte Sicherheit und Datenschutz und bietet Module, die eine sichere und private Kommunikation zwischen Servern in verschiedenen Regionen gewährleisten.
Implementing Federated Learning
Step 1: Setting Up the Environment
To implement FL, we will use TensorFlow Federated (TFF), a framework specifically designed for federated learning.
Install TensorFlow and TensorFlow Federated:
pip install tensorflow tensorflow-federated
Step 2: Define the Model
We will define a simple neural network model using TensorFlow.
import tensorflow as tf def create_keras_model(): return tf.keras.models.Sequential([ tf.keras.layers.Input(shape=(784,)), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(10, activation='softmax') ])
Step 3: Prepare the Data
For demonstration, we’ll use the MNIST dataset. In real-world applications, data would be distributed across different clients.
import tensorflow_federated as tff
def preprocess(dataset):
def batch_format_fn(element):
return (tf.reshape(element['pixels'], [-1, 784]),
tf.reshape(element['label'], [-1, 1]))
return dataset.repeat(10).shuffle(1000).batch(20).map(batch_format_fn).prefetch(10)
mnist_train, mnist_test = tf.keras.datasets.mnist.load_data()
def get_data_for_client(client_id, mnist_data):
client_data = {
'pixels': mnist_data[0][client_id * 6000:(client_id + 1) * 6000],
'label': mnist_data[1][client_id * 6000:(client_id + 1) * 6000]
}
return tf.data.Dataset.from_tensor_slices(client_data).map(lambda x, y: {'pixels': x, 'label': y})
clients_data = [get_data_for_client(i, mnist_train) for i in range(10)]
clients_data = [preprocess(client) for client in clients_data]
Step 4: Federated Learning Process
iterative_process = tff.learning.build_federated_averaging_process(
model_fn=create_keras_model,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.02),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=1.0)
)
state = iterative_process.initialize()
for round_num in range(1, 11):
state, metrics = iterative_process.next(state, clients_data)
print(f'Round {round_num}, Metrics={metrics}')
Reale Anwendungen des Föderierten Lernens
Föderiertes Lernen wird bereits in verschiedenen Branchen und Anwendungsfällen genutzt. Hier sind einige der häufigsten Anwendungen:
Smartphones
Smartphones sind eine weit verbreitete Plattform für föderiertes Lernen. Beispiele hierfür sind:
- Wortvorhersage: Vorhersage von Texten in Tastaturen.
- Gesichtserkennung: Anmeldung an Geräten mittels Gesichtserkennung.
- Spracherkennung: Verbesserungen für virtuelle Assistenten wie Siri oder Google Assistant.
Föderiertes Lernen personalisiert die Benutzererfahrung, während die Privatsphäre durch die Speicherung der Daten auf dem Gerät gewahrt bleibt.
Transport
Selbstfahrende Autos nutzen Computer Vision und maschinelles Lernen, um ihre Umgebung zu analysieren und in Echtzeit Entscheidungen zu treffen. Die kontinuierliche Anpassung an verschiedene Umgebungen erfordert das Lernen aus vielfältigen Datensätzen, um die Genauigkeit zu verbessern.
Föderiertes Lernen beschleunigt diesen Prozess, indem es den Modellen ermöglicht, lokal in jedem Fahrzeug zu lernen, was die Abhängigkeit von Cloud-basierten Ansätzen, die Latenzen einführen und das System verlangsamen können, verringert.
Zusammenfassend verbessert föderiertes Lernen die Robustheit und Effizienz von Modellen in realen Anwendungen, während es den Datenschutz und die Datensicherheit gewährleistet.
Fertigung
Im Fertigungssektor kann föderiertes Lernen verschiedene Prozesse durch die Nutzung breiterer Datensätze verbessern. Beispiele hierfür sind:
- Produktempfehlungssysteme: Traditionell wird die Produktnachfrage basierend auf individuellen Verkaufsdaten bewertet. Föderiertes Lernen kann Empfehlungssysteme verbessern, indem es eine breitere Palette von Datenquellen integriert, was zu genaueren und personalisierten Empfehlungen führt.
- Augmented Reality (AR) / Virtual Reality (VR): Diese Technologien werden für die Objekterkennung und Fernoperationen, einschließlich virtueller Montage, eingesetzt. Föderiertes Lernen kann Erkennungssysteme verfeinern und optimale Modelle für AR/VR-Anwendungen entwickeln.
- Überwachung der industriellen Umwelt: Föderiertes Lernen ermöglicht eine effiziente Zeitreihenanalyse von Umgebungsfaktoren, die von mehreren Sensoren verschiedener Unternehmen gesammelt werden. Dieser Ansatz wahrt die Datenprivatsphäre, während er Erkenntnisse aus verschiedenen Quellen zusammenführt, um die Überwachung und Vorhersagefähigkeiten zu verbessern.
Zusammenfassend verbessert föderiertes Lernen die Fertigung, indem es Empfehlungssysteme optimiert, AR/VR-Technologien vorantreibt und die Überwachung der industriellen Umwelt verbessert, wobei der Datenschutz gewahrt bleibt.
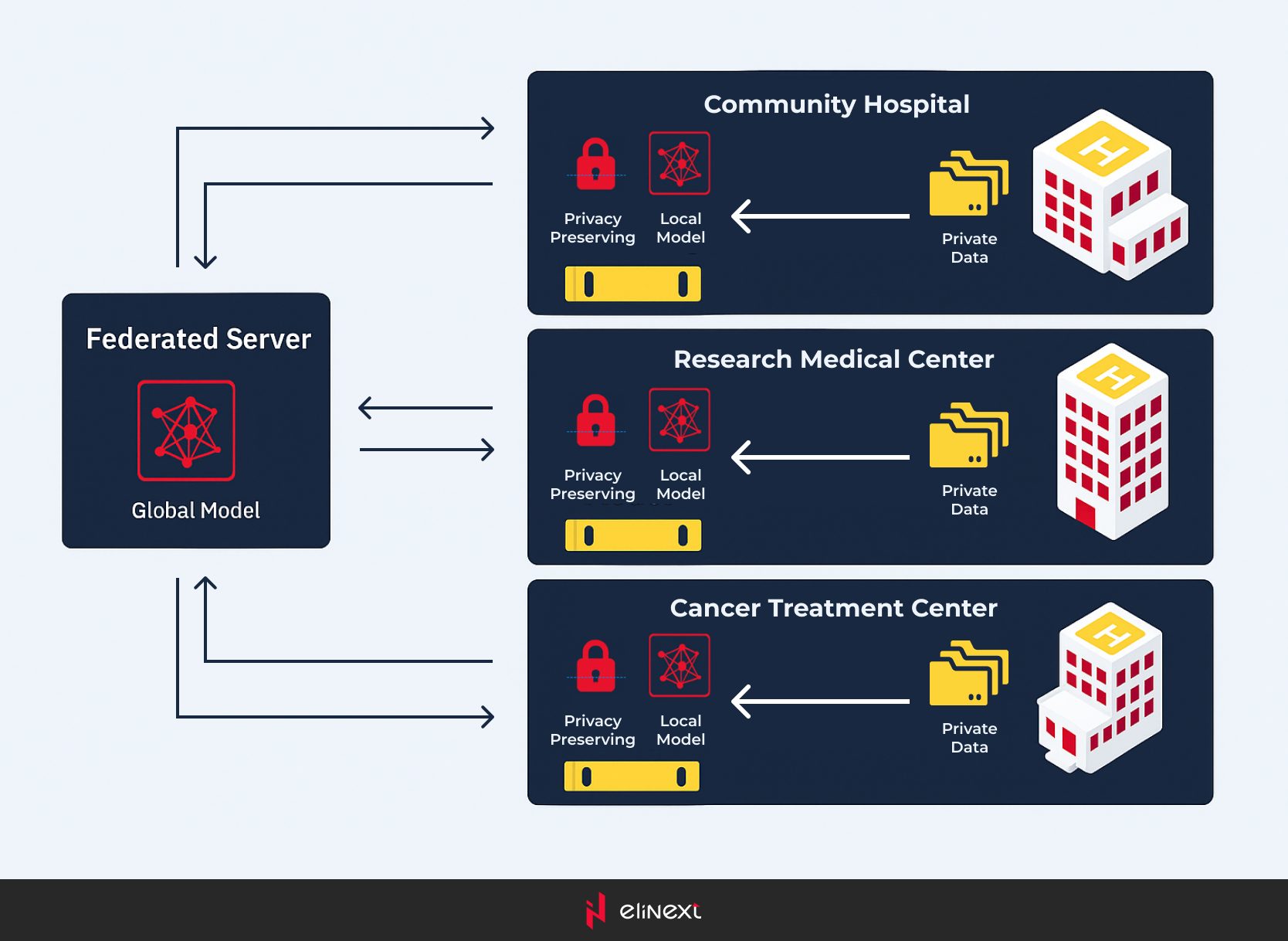
Gesundheitswesen
Die sensible Natur von Gesundheitsdaten und deren eingeschränkter Zugang aufgrund von Datenschutzproblemen erschweren es, maschinelle Lernsysteme in dieser Branche global zu skalieren.
Mit föderiertem Lernen können Modelle durch sicheren Zugang zu Daten von Patienten und medizinischen Einrichtungen trainiert werden, während die Daten an ihrem ursprünglichen Ort verbleiben. Es kann einzelnen Institutionen helfen, mit anderen zusammenzuarbeiten und macht es möglich, dass die Modelle aus mehr Datensätzen sicher lernen.
Zusätzlich kann föderiertes Lernen es Kliniken ermöglichen, Erkenntnisse über Patienten oder Krankheiten aus größeren demografischen Gebieten über lokale Institutionen hinaus zu gewinnen und kleineren ländlichen Krankenhäusern Zugang zu fortschrittlichen KI-Technologien zu gewähren.
Wichtige Erkenntnisse
Föderiertes Lernen bietet einen vielversprechenden Ansatz für dezentrales Daten-Training, der sowohl den Datenschutz als auch die Einhaltung von Vorschriften gewährleistet und gleichzeitig den kollaborativen Modellaufbau ermöglicht.
Föderiertes Lernen (FL) ermöglicht die Entwicklung genauerer und verallgemeinerbarer Modelle, während die Daten sicher auf den Client-Geräten verbleiben.
FL verwendet typischerweise drei Hauptstrategien: Zentralisiertes FL, Dezentralisiertes FL und Heterogenes FL. Zu den populären Algorithmen innerhalb dieser Strategien gehören FedSGD, FedAvg und FedDyn.
FedCV ist ein spezialisiertes FL-Framework, das für Anwendungen in der Computer Vision entwickelt wurde. Es schließt die Lücke zwischen Forschung und praktischer Implementierung, indem es eine einheitliche, benutzerfreundliche Bibliothek mit einer Vielzahl von Funktionalitäten bietet. Die praktischen Anwendungen von FedCV erstrecken sich über mehrere Branchen, einschließlich Gesundheitswesen, Transport und Fertigung.
