







Der Artikel behandelt die Phasen des MLOps-Lebenszyklus, wie Datenerfassung, Modellschulung, Bereitstellung und Überwachung. Es werden bewährte Verfahren für die Implementierung von MLOps hervorgehoben, einschließlich kontinuierlicher Integration und Bereitstellung, automatisierter Tests und Modellversionierung.
Was ist MLOps?
MLOps, kurz für Machine Learning Operations, ist eine Reihe von Praktiken, die die Entwicklung von Systemen für maschinelles Lernen (ML) und den Betrieb (Ops) kombinieren, um den gesamten ML-Lebenszyklus zu automatisieren und zu optimieren. Es orientiert sich an den DevOps-Grundsätzen, die darauf abzielen, die Zusammenarbeit zwischen Entwicklungs- und Betriebsteams in der Softwareentwicklung zu verbessern.
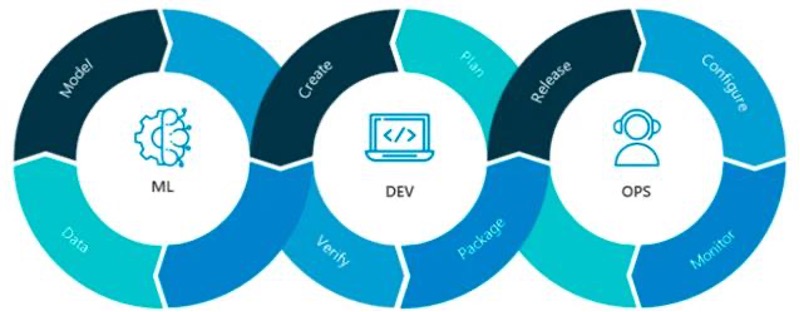
MLOps System
Quelle: Neal Analytics
Die Kernprinzipien und -praktiken von MLOps
Die Orchestrierung von Workflows ist ein zentrales Prinzip, das sicherstellt, dass alle Schritte im ML-Lebenszyklus, von der Datenerfassung bis zur Modellbereitstellung, nahtlos verwaltet werden. Versionsverwaltung ist entscheidend, um Änderungen an Daten, Modellen und Code nachzuverfolgen, was zur Konsistenz und Reproduzierbarkeit beiträgt. Reproduzierbarkeit gewährleistet, dass ML-Experimente zuverlässig wiederholt werden können, was zur Validierung von Ergebnissen unerlässlich ist. Die Zusammenarbeit zwischen Data Scientists, ML-Ingenieuren und Betriebsteams fördert die Kommunikation und Teamarbeit. Kontinuierliches Training und Evaluierung sind Praktiken, die Modelle mit neuen Daten auf dem neuesten Stand halten, um ihre Genauigkeit und Relevanz zu bewahren. Überwachung und Protokollierung sind unerlässlich, um die Modellleistung zu verfolgen und Probleme frühzeitig zu erkennen, damit Modelle wie erwartet funktionieren. Schließlich sind Feedback-Schleifen wichtig, um reale Daten und Erkenntnisse in die Modelle zurückzuführen und deren Leistung kontinuierlich zu verbessern.
Modellentwicklung:
Die Modellentwicklung ist die grundlegende Phase des MLOps-Lebenszyklus, in der sich Data Scientists und ML-Ingenieure auf den Aufbau von Machine-Learning-Modellen konzentrieren. Diese Phase umfasst mehrere entscheidende Schritte:
- Datensammlung und -vorbereitung: Erfassung und Vorverarbeitung von Daten, um sicherzustellen, dass sie sauber, relevant und analysierbereit sind.
- Feature Engineering: Erstellung und Auswahl von Merkmalen, die vom Modell zur Vorhersage verwendet werden.
- Modellauswahl: Auswahl geeigneter Machine-Learning-Algorithmen und -Techniken, basierend auf der jeweiligen Problemstellung.
- Training: Verwendung der vorbereiteten Daten, um das Modell zu trainieren und Parameter anzupassen, um die Leistung zu optimieren.
- Evaluierung: Bewertung der Modellleistung anhand verschiedener Metriken, um sicherzustellen, dass die gewünschte Genauigkeit und Zuverlässigkeit erreicht wird.
Vorproduktion:
In der Vorproduktionsphase liegt der Fokus auf dem Testen und Validieren des Modells, um sicherzustellen, dass es in realen Szenarien gut funktioniert:
- Validierung: Ausführen des Modells auf einem separaten Validierungsdatensatz, um Überanpassung und Generalisierung zu überprüfen.
- Hyperparameter-Optimierung: Anpassen der Hyperparameter des Modells, um die Leistung zu verbessern.
- Kreuzvalidierung: Verwendung von Techniken wie k-facher Kreuzvalidierung, um die Robustheit des Modells sicherzustellen.
- A/B-Tests: Vergleich des neuen Modells mit bestehenden Modellen, um festzustellen, ob es Verbesserungen bietet.
Bereitstellung:
Die Bereitstellung umfasst Strategien, um das Modell aus einer Entwicklungsumgebung in die Produktion zu überführen:
- Containerisierung: Verpacken des Modells und seiner Abhängigkeiten in Container, mithilfe von Tools wie Docker.
- CI/CD-Pipelines: Implementierung von Continuous Integration und Continuous Deployment Pipelines, um den Bereitstellungsprozess zu automatisieren.
- Skalierbarkeit: Sicherstellen, dass das Modell erhöhte Lasten bewältigen und bei Bedarf skaliert werden kann.
- Rollback-Mechanismen: Etablierung von Verfahren, um auf frühere Versionen zurückzugreifen, falls bei der neuen Bereitstellung Probleme auftreten.
Überwachung:
Sobald das Modell bereitgestellt ist, ist eine kontinuierliche Überwachung unerlässlich, um seine Leistung und Stabilität zu gewährleisten:
- Leistungsmetriken: Verfolgen von wichtigen Leistungsindikatoren (KPIs) wie Genauigkeit, Latenz und Durchsatz.
- Drift-Erkennung: Identifizierung von Änderungen in der Datenverteilung, die die Modellleistung beeinflussen könnten.
- Protokollierung: Führen detaillierter Protokolle von Modellvorhersagen und Systemverhalten für die Fehlersuche.
- Warnungen und Benachrichtigungen: Einrichten von Warnmeldungen, um das Team bei Anomalien oder Leistungsabfällen zu informieren.
Durch die Einhaltung dieser Phasen können Unternehmen den gesamten MLOps-Lebenszyklus effizient verwalten.
Tools und Technologien
Im sich schnell entwickelnden Bereich des maschinellen Lernens sind mehrere Tools entstanden, um den MLOps-Lebenszyklus zu optimieren und zu verbessern. Hier sind einige der beliebtesten:
- Kubeflow: Eine Open-Source-Plattform, die darauf ausgelegt ist, die Bereitstellung von maschinellen Lern-Workflows auf Kubernetes einfach, portabel und skalierbar zu machen. Kubeflow bietet ein umfangreiches Set an Tools für die Entwicklung, Orchestrierung, Bereitstellung und Verwaltung skalierbarer und portabler Machine-Learning-Workloads.
- MLflow: Eine kostenlose Open-Source-Plattform, die den gesamten Lebenszyklus des maschinellen Lernens verwaltet. MLflow bietet Werkzeuge für Experiment-Tracking, Modellversionierung und Bereitstellung. Es ist darauf ausgelegt, mit jeder ML-Bibliothek, jedem Algorithmus und jedem Bereitstellungstool zu arbeiten.
- TensorFlow Extended (TFX): Eine End-to-End-Plattform zur Bereitstellung von produktionsreifen ML-Pipelines. TFX bietet Komponenten zur Datenvalidierung, Modelltraining, Modellanalyse und Bereitstellung und ist damit eine robuste Wahl für produktionsreife ML-Workflows.
Werkzeugvergleich
Bei der Auswahl eines MLOps-Tools ist es wichtig, die spezifischen Anforderungen Ihres Projekts und Ihrer Organisation zu berücksichtigen. Hier ist ein Vergleich der Vor- und Nachteile dieser beliebten Tools:
1. Kubeflow
Vorteile:
- Nahtlose Integration mit Kubernetes, was es hoch skalierbar macht.
- Umfassende Suite von Tools für verschiedene Phasen des ML-Lebenszyklus.
- Starke Community-Unterstützung und kontinuierliche Updates.
Nachteile:
- Steilere Lernkurve aufgrund seiner Komplexität.
- Erfordert Kubernetes-Expertise, was für einige Teams eine Hürde sein könnte.
2. MLflow
Vorteile:
- Einfach einzurichten und zu bedienen, mit einer intuitiven Benutzeroberfläche.
- Unterstützt eine breite Palette von ML-Bibliotheken und Tools.
- Flexibel und kann in bestehende Workflows integriert werden.
Nachteile:
- Eingeschränkte integrierte Unterstützung für Orchestrierung im Vergleich zu Kubeflow.
- Einige erweiterte Funktionen erfordern zusätzliche Anpassungen.
3. TensorFlow Extended (TFX)
Vorteile:
- Entwickelt für produktionsreife ML-Pipelines, was Robustheit und Zuverlässigkeit gewährleistet.
- Starke Integration mit TensorFlow, ideal für TensorFlow-Nutzer.
- Umfassende Komponenten für Datenvalidierung, Modelltraining und Bereitstellung.
Nachteile:
- Ideal für TensorFlow-basierte Projekte, was jedoch die Kompatibilität mit anderen Frameworks einschränken kann.
- Kann für Anfänger schwierig einzurichten und zu konfigurieren sein.
Die Wahl der MLOps-Tools hängt von Ihren spezifischen Anforderungen, der bestehenden Infrastruktur und der Expertise Ihres Teams ab. Das Verständnis der Stärken und Einschränkungen jedes Tools wird Ihnen helfen, eine fundierte Entscheidung zu treffen und Ihre Machine-Learning-Operationen zu optimieren.
Praxisbeispiele:
Hier betrachten wir einige reale Erfolgsgeschichten und wertvolle Erkenntnisse von Organisationen, die MLOps implementiert haben.
1. Merck Research Labs
Merck Research Labs nutzte MLOps, um die Impfstoffforschung und -entdeckung zu beschleunigen. Durch die Implementierung automatisierter ML-Pipelines konnten sie die Zeit für die Entwicklung und Bereitstellung von Modellen erheblich verkürzen. Dieser Ansatz beschleunigte nicht nur die Forschung, sondern verbesserte auch die Reproduzierbarkeit und Zuverlässigkeit ihrer ML-Modelle.
2. Booking.com
Booking.com entwickelte eine eigene MLOps-Plattform namens Michelangelo, um ihr umfangreiches Portfolio an ML-Modellen zu verwalten. Diese Plattform ermöglichte es ihnen, ihre ML-Kapazitäten zu skalieren und ihr Modellportfolio um das 150-fache zu erweitern. Das Ergebnis war eine personalisiertere Benutzererfahrung und eine verbesserte betriebliche Effizienz.
3. AgroScout
AgroScout, ein Anbieter von KI- und Computer-Vision-Lösungen für die Landwirtschaft, nutzte die MLOps-Plattform von ClearML, um ein 100-faches Datenvolumen und ein 50-faches Experimentvolumen zu bewältigen. Durch diese Implementierung konnten sie ihre Produktionszeit um 50 % verkürzen und ihren Kunden genauere und zeitgerechtere Einblicke liefern.
4. EY (Ernst & Young)
EY führte MLOps ein, um die Bereitstellung von Modellen zu beschleunigen und die Einhaltung von regulatorischen Standards zu verbessern. Durch die Standardisierung ihrer ML-Workflows und die Automatisierung der Bereitstellungsprozesse konnte EY Modelle schneller bereitstellen und sicherstellen, dass sie alle erforderlichen Compliance-Anforderungen erfüllten.
5. Starbucks Indien
Starbucks Indien setzte MLOps ein, um ihre datengesteuerten Strategien zu optimieren. Durch die Integration von MLOps-Praktiken verbesserten sie die Genauigkeit ihrer Verkaufsprognosen und optimierten das Bestandsmanagement, was zu einer höheren Kundenzufriedenheit und weniger Verschwendung führte.
Fazit
In diesem Artikel haben wir den umfassenden MLOps-Lebenszyklus untersucht und dabei Phasen wie Datensammlung, Modelltraining, Implementierung und Überwachung behandelt. Wir haben bewährte Methoden für die Umsetzung von MLOps hervorgehoben, einschließlich kontinuierlicher Integration und Bereitstellung, automatisierter Tests und Modellversionierung. Außerdem haben wir einen Überblick über MLOps gegeben und dessen Rolle bei der Kombination von Entwicklung und Betrieb von maschinellen Lernsystemen zur Optimierung des gesamten ML-Lebenszyklus betont.
Der Artikel deckte auch die Modellentwicklung ab, indem Schritte wie Datensammlung und -aufbereitung, Merkmalsauswahl, Modellwahl, Training und Evaluierung detailliert beschrieben wurden. In der Phase vor der Produktion haben wir Validierung, Hyperparameter-Tuning, Kreuzvalidierung und A/B-Tests besprochen. Für die Implementierung haben wir Strategien wie Containerisierung, CI/CD-Pipelines, Skalierbarkeit und Rollback-Mechanismen untersucht. Überwachungstechniken umfassten Leistungskennzahlen, Drift-Erkennung, Protokollierung und Alarme.
Wir haben beliebte MLOps-Tools wie Kubeflow, MLflow und TensorFlow Extended (TFX) überprüft und ihre Vor- und Nachteile verglichen, um Organisationen zu helfen, das richtige Werkzeug basierend auf ihren spezifischen Bedürfnissen auszuwählen. Schließlich haben wir Erfolgsgeschichten aus der Praxis von Organisationen wie Merck Research Labs, Booking.com, AgroScout, EY und Starbucks Indien geteilt und die dabei gewonnenen Erkenntnisse aus ihren MLOps-Implementierungen hervorgehoben.
Durch die Befolgung dieser Phasen und Prinzipien können Organisationen den gesamten MLOps-Lebenszyklus effektiv verwalten und sicherstellen, dass ihre maschinellen Lernmodelle robust, zuverlässig und im Einklang mit geschäftlichen und ethischen Standards stehen.
