







Diabetes ist eine Krankheit, bei der Zeit eine entscheidende Rolle spielt. Regelmäßige augenärztliche Untersuchungen und Analysen von Netzhautbildern können zur frühzeitigen Erkennung und Behandlung beitragen. Bei Patienten im mittleren bis schweren Stadium der Krankheit sind häufige augenärztliche Untersuchungen notwendig, um den Fortschritt der diabetischen Retinopathie zu überwachen. Dies ist jedoch nicht immer möglich aufgrund der hohen Anzahl von Patienten und des Mangels an Ärzten.
Hier kann künstliche Intelligenz hilfreich sein. Spezialisierte Systeme zur Analyse von Netzhautbildern, die mit modernen Methoden der künstlichen Intelligenz entwickelt wurden, können Augenärzten dabei helfen, die Überwachung des Zustands des Augenhintergrunds der Patienten zu vereinfachen.
Ziel dieses Artikels ist es, die Erfahrungen bei der Implementierung eines Systems zur Erkennung und Klassifizierung der diabetischen Retinopathie mit Hilfe von KI-Werkzeugen zu teilen.
Hintergrund
Wie allgemein bekannt ist, gehören Diabetes mellitus und seine Komplikationen zu den gravierendsten medizinischen, sozialen und wirtschaftlichen Problemen des modernen Gesundheitswesens. Diabetische Retinopathie ist eine Komplikation des Diabetes mellitus, die die Blutgefäße der Netzhaut des Auges betrifft. Die Retinopathie beginnt völlig asymptomatisch und der Patient bemerkt sie lange Zeit nicht. Der Verlust oder die Verringerung der Sehschärfe signalisiert einen irreversiblen Komplikationsprozess. Ein effektives System zur Erkennung und Behandlung der diabetischen Retinopathie kann das Risiko der Erblindung und die damit verbundenen wirtschaftlichen Kosten erheblich reduzieren. Die moderne Augenheilkunde verfügt über das Wissen, um diese Komplikation des Diabetes zu bekämpfen, einschließlich der Laserkoagulation und der Vitrektomie. Die Zahl der Diabetiker wächst, und die diabetische Retinopathie ist eine der schwersten Komplikationen, die oft zur Erblindung führt. Die Laserbehandlung eines Patienten ist 12-mal günstiger als die Sozialleistungen für eine blinde Person. In der Praxis gibt es auch Fälle, in denen der Patient lange Zeit nichts von seinem Diabetes mellitus ahnt, aber die Erkennung einer diabetischen Retinopathie auf das Vorhandensein einer Grunderkrankung hinweisen kann. Laut der Weltgesundheitsorganisation (WHO) gibt es fünf Stadien der Krankheit:
0 – Keine DR
1 – Mild
2 – Moderat
3 – Schwer
4 – Proliferative DR
Laut WHO gibt es folgende Hauptprobleme: Mikroaneurysmen sind lokale Erweiterungen der Netzhautgefäße, die mit einer übermäßigen Durchlässigkeit im Makulabereich verbunden sind und zu einem Makulaödem führen; Blutungen; „harte“ Exsudate; „weiche“ Exsudate; Netzhautödem. Einige dieser Probleme sind auf dem Bild eines Patienten zu sehen, der an Stadium 4 der diabetischen Retinopathie leidet:
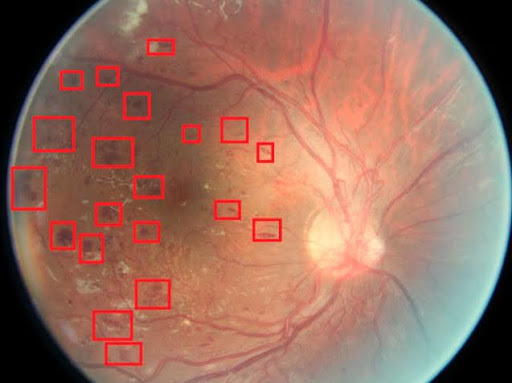
Daher wurde die Aufgabe gestellt, für eine medizinische Klinik ein Softwareprodukt zur Klassifizierung der diabetischen Retinopathie in 4 Stadien zu entwickeln. Die Hauptarbeit zur Erreichung des Ziels bestand aus folgenden Phasen: Erstellung eines Forschungsplans, Suche nach einem geeigneten Datensatz für Training und Validierung, Forschung und Experimente mit bestehenden neuronalen Netzwerkarchitekturen, Implementierung des Systemcodes basierend auf dem ausgewählten neuronalen Netzwerk, Modelltraining, Analyse der Ergebnisse an Bildern durch das Krankenhaus.
Herausforderungen und Lösungen
Das erste Problem, das bei der Lösung dieser technischen Aufgabe gelöst werden musste, war die Frage, woher man eine Trainingsstichprobe bekommen sollte. Im Zuge der Untersuchung dieses Problems wurden viele Quellen auf die Verfügbarkeit von fertigen Datensätzen mit Fundusbildern analysiert. Eine kurze Übersicht über im Internet unter einer freien Lizenz verteilte fertige Datensätze ist in der Tabelle dargestellt:

Seit 2015 steht auf der Ressource kaggle.com ein umfangreicher Datensatz zum Download bereit, der aus 35.126 Bildern für das Netztraining und 53.576 Bildern zur Validierung der Ergebnisse besteht. Daher wurde genau dieser Datensatz für das Training in diesem Projekt verwendet.
Das zweite Problem, das bei jedem ML-Ingenieur auftritt, der ein Bildklassifizierungsproblem löst, ist die Auswahl eines geeigneten neuronalen Netzwerks aus einer großen Menge bestehender Netzwerke. Im Folgenden wird die Qualitätsformel der oben genannten Convolutional Neural Networks in Abhängigkeit von Merkmalen wie Breite, Tiefe und Auflösung des Netzwerks vorgestellt:

Die Formel zeigt, dass die Genauigkeit des Netzwerks proportional zur Tiefe des Netzwerks zunimmt, was ein gutes Zeichen ist, aber es gibt ein Problem mit der Gradientenschwächung. Dieses Problem wird detailliert in dem Artikel „Performance Comparison of CNN Models Using Gradient Flow Analysis“ von Saul-Hyun Noah aus dem Jahr 2021 beschrieben. Ein weiterer Weg zur Erhöhung der Genauigkeit des Netzwerks ist die Breite. Aus der Formel geht hervor, dass je größer die Breite des Netzwerks ist, desto genauer ist das Netzwerk. Gleichzeitig besteht eine quadratische Abhängigkeit des Netzwerks von seiner Breite. Ebenso ist es mit der Auflösung zur Erhöhung der Genauigkeit des Netzwerks. Das heißt, je höher die Eingangsauflösung, desto genauer ist das Netzwerk. Auch hier zeigt die Formel, dass eine quadratische Abhängigkeit des Netzwerks von der Eingangsauflösung besteht.
Die Autoren des Artikels [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks] schlagen eine neue zusammengesetzte Skalierungsmethode vor, die Tiefe/Breite/Auflösung mit festen Proportionen zwischen ihnen gleichmäßig skaliert. Als Ergebnis erhalten die Autoren eine neue Klasse von Modellen, die EfficientNet genannt wird und bereits die optimalsten Startgewichtungskoeffizienten enthält. Es gibt mehrere Untergruppen dieser Architekturen eines bestimmten Netzwerks von B0 bis B7, je nach erforderlicher Genauigkeit. Das Funktionsschema dieser Netzwerke wird im Vergleich zu anderen Netzwerken in der Abbildung gezeigt. Dieses Netzwerk wurde zur Lösung der Aufgabe ausgewählt. Der Vergleich von EfficientNet mit anderen Netzwerken ist auf dem Bild zu sehen:
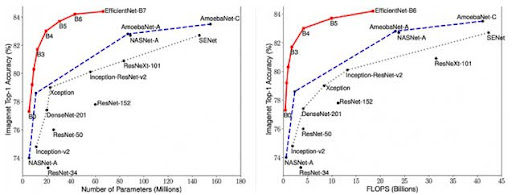
Der nächste wichtige Schritt war der Aufbau eines Modells basierend auf dem oben genannten EfficientNet-Netzwerk. Schauen wir uns Schritt für Schritt an, was in jeder Zeile passiert:
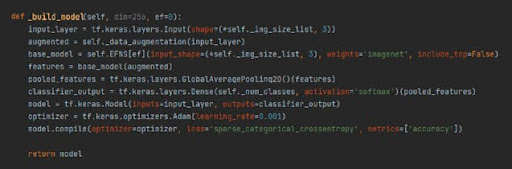
- Eingabeschicht:
- input_layer = tf.keras.layers.Input(shape=(*self._img_size_list, 3)):
Diese Zeile erstellt eine Eingabeschicht für das Modell, die Bilder der Form erwartet, die durch eine Liste definiert ist, welche die Höhe und Breite der Bilder angibt. Die 3 zeigt an, dass die Bilder 3 Farbkanäle (RGB) haben.
- Datenaugmentation:
- augmented = self._data_augmentation(input_layer):
Wendet Datenaugmentation auf die Eingabebilder an, indem eine Methode verwendet wird, die anderswo in der Klasse definiert ist. Datenaugmentation ist eine Technik, die verwendet wird, um die Vielfalt der Trainingsdaten zu erhöhen, ohne tatsächlich neue Daten zu sammeln, indem zufällige Transformationen wie Drehung, Skalierung usw. angewendet werden.
- Basis-Modell:
- base_model = self.EFNS[ef](input_shape=(*self._img_size_list, 3), weights=’imagenet‘, include_top=False):
Lädt eines der EfficientNet-Modelle als Basis-Modell mit vorab trainierten Gewichten von ImageNet. Das zweite Argument zeigt an, dass die oberste Schicht des Netzwerks, die typischerweise für die Klassifikation verwendet wird, nicht enthalten ist, sodass benutzerdefinierte Schichten hinzugefügt werden können.
- Merkmalextraktion:
- features = base_model(augmented):
Leitet die augmentierten Bilder durch das Basis-Modell, um Merkmale zu extrahieren.
- Pooling-Schicht:
- pooled_features = tf.keras.layers.GlobalAveragePooling2D()(features):
Wendet globales durchschnittliches Pooling auf die Merkmale an, was die räumlichen Dimensionen (Höhe und Breite) auf einen einzelnen Wert pro Kanal reduziert. Dies ist nützlich, um die Informationen in eine Form zu verdichten, die für die Klassifikation geeignet ist.
- Ausgabeschicht:
- classifier_output = tf.keras.layers.Dense(self._num_classes, activation=’softmax‘)(pooled_features):
Fügt eine vollständig verbundene Schicht mit einer Anzahl von Einheiten hinzu, die der Anzahl der Klassen entspricht. In diesem Fall entspricht diese Anzahl der Anzahl der Krankheitsstadien. Die Softmax-Aktivierungsfunktion wird verwendet, um die Wahrscheinlichkeitsverteilung über die Klassen zu berechnen.
- Modellerstellung:
- model = tf.keras.Model(inputs=input_layer, outputs=classifier_output):
Erstellt das Keras-Modell mit den definierten Eingabe- und Ausgabeschichten.
- Kompilierung:
- optimizer = tf.keras.optimizers.Adam(learning_rate=0.001):
Initialisiert den Adam-Optimierer mit einer Lernrate von 0.001.
- model.compile(optimizer=optimizer, loss=’sparse_categorical_crossentropy‘, metrics=[‚accuracy‘]):
Kompiliert das Modell mit dem Adam-Optimierer, verwendet sparse_categorical_crossentropy als Verlustfunktion (häufig bei Aufgaben der Mehrklassenklassifikation verwendet) und verfolgt die Genauigkeitsmetrik.
Danach war es notwendig, das Modell mit Trainingsdaten zu trainieren. Insgesamt wurden 5 Trainingsphasen durchgeführt:
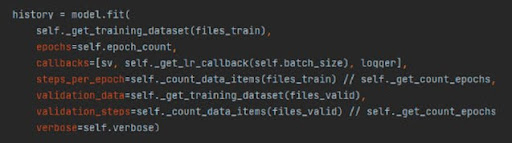
- Vorbereitung des Trainingsdatensatzes:
- self._get_training_dataset(files_train):
Diese Methode soll einen vorverarbeiteten Datensatz zurückgeben, der für das Training bereit ist, unter Verwendung der Trainingsdateien.
- Festlegung der erforderlichen Anzahl von Epochen:
- epochs=self.epoch_count:
Die Anzahl der Durchläufe, die der Datensatz in Vorwärts- und Rückwärtsrichtung durch das neuronale Netzwerk machen soll.
- Callbacks zur Anzeige interner Zustände und Statistiken:
- sv:
Modell-Checkpoint-Callback, um das Modell in bestimmten Abständen zu speichern.
- self._get_lr_callback(self.batch_size):
Passt die Lernrate basierend auf der Batch-Größe oder anderen Kriterien an.
- logger:
Protokolliert die Ergebnisse der Epochen in einer CSV-Datei.
- Anzahl der Schritte pro Epoche:
- steps_per_epoch:
Die Anzahl der Batches von Proben, die während jeder Epoche ausgeführt werden sollen, was der Gesamtanzahl der Trainingsartikel geteilt durch die Batch-Größe und dann durch die Anzahl der Replikate (falls das Training auf mehrere Geräte verteilt wird) entspricht.
- Vorbereitung des Validierungsdatensatzes:
- validation_data:
Erhält die Verlust- und Qualitätsmetriken nach Abschluss jeder Epoche.
- Anzahl der Schritte pro Epoche für die Validierung:
- validation_steps:
Ähnlich wie steps_per_epoch, jedoch für den Validierungsdatensatz.
- Fortschrittsbalken während des Trainings:
- verbose:
Dies steuert die Ausführlichkeit der Ausgabe während des Trainings (z. B. ob ein Fortschrittsbalken angezeigt wird).
Modelltraining
Das Training erfolgt in 5 Phasen (Folds). In jeder Phase werden die Daten zufällig gemischt. Ein Fünftel der Daten wird zur Überprüfung der Trainingsgenauigkeit verwendet (Validierungssatz in den Begriffen von TensorFlow), die restlichen Daten werden zum Trainieren des Modells verwendet. Somit können sich die Trainingsdaten von Phase zu Phase unterscheiden, was es ermöglicht, die Gewichtungskoeffizienten mit den besten Ergebnissen auszuwählen.
Die TF-Bibliothek ermöglicht es, den Erfolg des Modelltrainings zu bestimmen, indem kritische Daten in jeder Trainingsphase gespeichert werden. Der absolute Wert der Verluste (Loss) und die Genauigkeit der Vorhersagen (Accuracy) werden als solche Daten verwendet.
Experimentell wurde festgestellt, dass die beste Trainingsleistung bei einer Anzahl von 25 Trainingsepochen erreicht wird. Die NVIDIA RTX 3060 GPU mit 12 GB Videospeicher ermöglicht die parallele Verarbeitung eines Pakets aus den Quelldaten.
Modelldaten vor Beginn des Trainings:
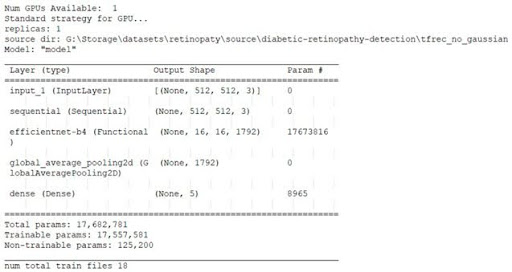
Das Modell der fünften Phase kann als das beste Modell für den praktischen Einsatz betrachtet werden, da die Verlust- und Genauigkeitskurven häufiger übereinstimmen als in anderen Trainingsphasen. Aus diesem Grund sind unten Visualisierungen des Modelltrainings für die fünfte Phase dargestellt. Der fünfte Trainingszyklus dauert 72.900 Sekunden (20 Stunden 15 Minuten 0 Sekunden). Die Fehlermatrizen des Trainings sind in der Abbildung gezeigt:
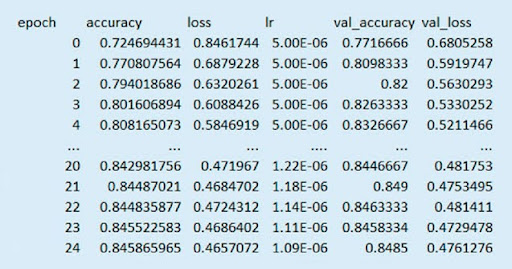
Die Ereignisgeschichte in der fünften Trainingsphase:

Genauigkeit des Trainings in der fünften Trainingsphase:
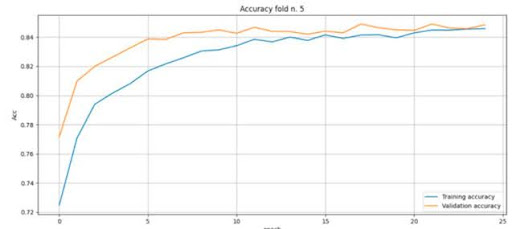
Die Verlustmenge in der fünften Trainingsphase:

Aus den Trainingsergebnissen ist ersichtlich, dass das trainierte neuronale Netzwerk in der Lage ist, den Grad der diabetischen Retinopathie mit einer Wahrscheinlichkeit von 85 Prozent zu bestimmen.
Tests und Experimente
Nach dem Testen des Modells wurden die folgenden Indikatoren ermittelt:
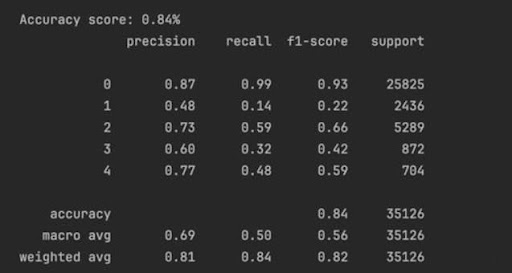
Das Modell ist sehr effektiv bei der Vorhersage der Klasse 0 (keine Retinopathie), hat jedoch Schwierigkeiten mit dem ersten Stadium der Krankheit und zeigt moderate Ergebnisse für die anderen Klassen. Die Gesamttreffgenauigkeit ist hoch, aber der niedrige Recall für einige Klassen zeigt, dass das Modell möglicherweise eine signifikante Anzahl positiver Fälle für diese Klassen übersieht. Diese Situation ist jedoch normal, da das erste Stadium der Krankheit nicht immer eindeutig erkannt werden kann, selbst anhand von Fundusfotografien. In solchen Fällen werden in der Medizin andere Tests und Techniken angewendet.
Der nächste Schritt bestand darin, das Experiment durchzuführen und das Modell in der Praxis an einem Patienten aus einer realen medizinischen Klinik zu testen. Während der Entwicklung dieser Software wurde mit Kollegen aus einer medizinischen Klinik zusammengearbeitet, die dieses Foto eines anonymen Patienten zur Verfügung stellte. Es war im Voraus bekannt, dass der Patient am zweiten Stadium der Retinopathie litt. Die Fotografie hat eine nicht standardmäßige Auflösung von 1750 x 1462 Pixeln sowie eine unkonventionelle Form. Dies erklärt sich durch das Bestreben, den gesamten Bereich des Fundus des Patienten so weit wie möglich abzudecken, und wird durch die Besonderheiten der Arbeitsweise jedes Augenarztes bestimmt:
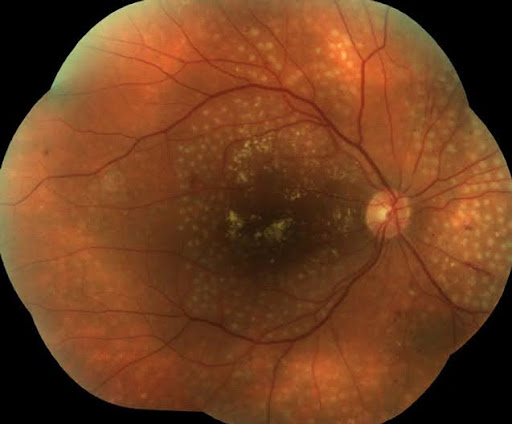
Schauen wir uns das Ergebnis des Experiments an:

Wie aus den Ergebnissen der Software ersichtlich ist, wurde das zweite Stadium der Retinopathie trotz der nicht standardmäßigen Parameter der Fundusfotografie erfolgreich bestätigt.
Fazit
Dieser Artikel zeigte, wie eine Anwendung auf Basis von neuronalen Netzwerken erstellt wird. Es wurden die wichtigsten Phasen betrachtet, wie die Begründung der Wahl eines fertigen neuronalen Netzwerks, die Erstellung des neuronalen Netzwerks basierend auf einem bereits vorhandenen tiefen neuronalen Netzwerk, das Training des Netzwerks, die Qualitätsbewertung usw.
Die in diesem Projekt durchgeführte Forschung hat gezeigt, dass tiefe neuronale Netzwerke in der Lage sind, den Schweregrad der Krankheit effektiv zu bestimmen. Der gewichtete durchschnittliche F1-Score zur Erkennung von Pathologien von 82% ermöglicht es, die Arbeit eines Augenarztes erheblich zu verbessern und die Anzahl der Diagnosefehler zu reduzieren.
Die entwickelte Anwendung wurde zusätzlich in einer medizinischen Klinik getestet. Das Testen wurde an einer Stichprobe von 1000 Fotografien echter Patienten mit Retinopathie durchgeführt. Basierend auf den Ergebnissen einer manuellen Überprüfung durch einen medizinischen Fachmann wurde Retinopathie in 859 Fotografien erkannt, was die Richtigkeit der Erkennung dieser Krankheit bewies. Es ist wichtig zu erwähnen, dass die entwickelte Software nicht das Hauptwerkzeug zur Identifizierung der Krankheit ist, sondern nur ein Hilfsmittel in einer der Phasen der Arbeit zwischen einem Patienten und einer medizinischen Klinik.
Das entwickelte Programm, das die Vorbereitung von Daten, das Training eines Modells und die Vorhersage des Schweregrades der diabetischen Retinopathie ermöglicht, wurde somit in den Behandlungsprozess einer medizinischen Klinik eingeführt.
